前言: trace 系统用于收集内核的数据,本文介绍在 Node.js 中 trace 的架构和实现,因为 Node.js 的 trace 系统是基于 V8 的,所以也会介绍 V8 部分。因为实现细节比较多,逻辑也比较复杂,有兴趣的同学可以配合源码一起阅读或者看一下前面的相关文章。
因为 Node.js 的 trace 体系是基于 V8 的,所以先来看 V8 的实现。
1 V8 的实现
1.1. TraceObject
TraceObject 对应用于表示一个 trace 事件的信息。下面是一次 trace 事件需要保存的核心字段。
1
2
3
4
5
6
7
8
9
10
11
12
13 | class V8_PLATFORM_EXPORT TraceObject {
private:
int pid_;
int tid_;
char phase_;
const char* name_;
const char* scope_;
int64_t ts_;
int64_t tts_;
uint64_t duration_;
uint64_t cpu_duration_;
// 忽略其他字段
};
|
1.2 TraceWriter
TraceWriter 用于表示消费者,整个 trace 系统中可以有多个消费者。
| class V8_PLATFORM_EXPORT TraceWriter {
public:
// 消费数据,只会保存在内存里,必要的时候再进行真正的处理
virtual void AppendTraceEvent(TraceObject* trace_event) = 0;
// 真正处理数据的函数
virtual void Flush() = 0;
// 获取一个 json writer,即把 trace 数据进行 json 格式化
static TraceWriter* CreateJSONTraceWriter(std::ostream& stream)
};
|
1.3 TraceBufferChunk
TraceBufferChunk 用于临时保存 trace 数据,因为数据会现在内存中缓存,具体由 TraceBufferChunk 进行组织和保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | class V8_PLATFORM_EXPORT TraceBufferChunk {
public:
explicit TraceBufferChunk(uint32_t seq);
void Reset(uint32_t new_seq);
// 数组是否满了
bool IsFull() const { return next_free_ == kChunkSize; }
// 获取一个空闲的元素地址
TraceObject* AddTraceEvent(size_t* event_index);
TraceObject* GetEventAt(size_t index) { return &chunk_[index]; }
uint32_t seq() const { return seq_; }
size_t size() const { return next_free_; }
static const size_t kChunkSize = 64;
private:
size_t next_free_ = 0;
TraceObject chunk_[kChunkSize];
uint32_t seq_;
};
|
1.4 TraceBuffer
TraceBuffer 是对 TraceBufferChunk 的封装,本身不存储数据。
| class V8_PLATFORM_EXPORT TraceBuffer {
public:
virtual TraceObject* AddTraceEvent(uint64_t* handle) = 0;
virtual TraceObject* GetEventByHandle(uint64_t handle) = 0;
virtual bool Flush() = 0;
static const size_t kRingBufferChunks = 1024;
static TraceBuffer* CreateTraceBufferRingBuffer(size_t max_chunks, TraceWriter* trace_writer);
};
|
1.5 TraceConfig
TraceConfig 是用于管理 category,记录需要收集哪类 category 数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | class V8_PLATFORM_EXPORT TraceConfig {
public:
// 获取默认 category => v8
static TraceConfig* CreateDefaultTraceConfig();
// 获取订阅的 category
const StringList& GetEnabledCategories() const {
return included_categories_;
}
// 新增 category
void AddIncludedCategory(const char* included_category);
// 是否开启了收集该 cateogry 数据
bool IsCategoryGroupEnabled(const char* category_group) const;
private:
StringList included_categories_;
};
|
1.6 TracingController
TracingController 是非常核心的类,用于管理整个 trace 系统。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | class TracingController {
public:
// 需要收集哪类 cateogry 的 trace 数据,子类实现
virtual const uint8_t* GetCategoryGroupEnabled(const char* name) {
static uint8_t no = 0;
return &no;
}
// 产生 trace 数据
virtual uint64_t AddTraceEvent(...) {
return 0;
}
virtual uint64_t AddTraceEventWithTimestamp(...) {
return 0;
}
virtual void UpdateTraceEventDuration(...) {}
class TraceStateObserver {
public:
virtual ~TraceStateObserver() = default;
virtual void OnTraceEnabled() = 0;
virtual void OnTraceDisabled() = 0;
};
// 管理 trace 系统的观察者
virtual void AddTraceStateObserver(TraceStateObserver*) {}
virtual void RemoveTraceStateObserver(TraceStateObserver*) {}
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | class V8_PLATFORM_EXPORT TracingController : public V8_PLATFORM_NON_EXPORTED_BASE(v8::TracingController) {
public:
// 设置保存数据的 buffer
void Initialize(TraceBuffer* trace_buffer);
// 判断是否需要收集 category 为 category_group 的数据
const uint8_t* GetCategoryGroupEnabled(const char* category_group) override;
// 把数据保存到 buffer 中
uint64_t AddTraceEvent(...) override;
uint64_t AddTraceEventWithTimestamp(...) override;
void UpdateTraceEventDuration(...) override;
// 根据订阅的 category 设置开启标记,这时候才会收集 trace 数据
void StartTracing(TraceConfig* trace_config);
void StopTracing();
private:
// 根据订阅的 category 设置开启标记, StartTracing 中使用
void UpdateCategoryGroupEnabledFlag(size_t category_index);
void UpdateCategoryGroupEnabledFlags();
std::unique_ptr<base::Mutex> mutex_;
// 订阅的 category
std::unique_ptr<TraceConfig> trace_config_;
// 订阅者,StartTracing 时通知它们
std::unordered_set<v8::TracingController::TraceStateObserver*> observers_;
// 保存数据的 buffer
std::unique_ptr<TraceBuffer> trace_buffer_;
};
|
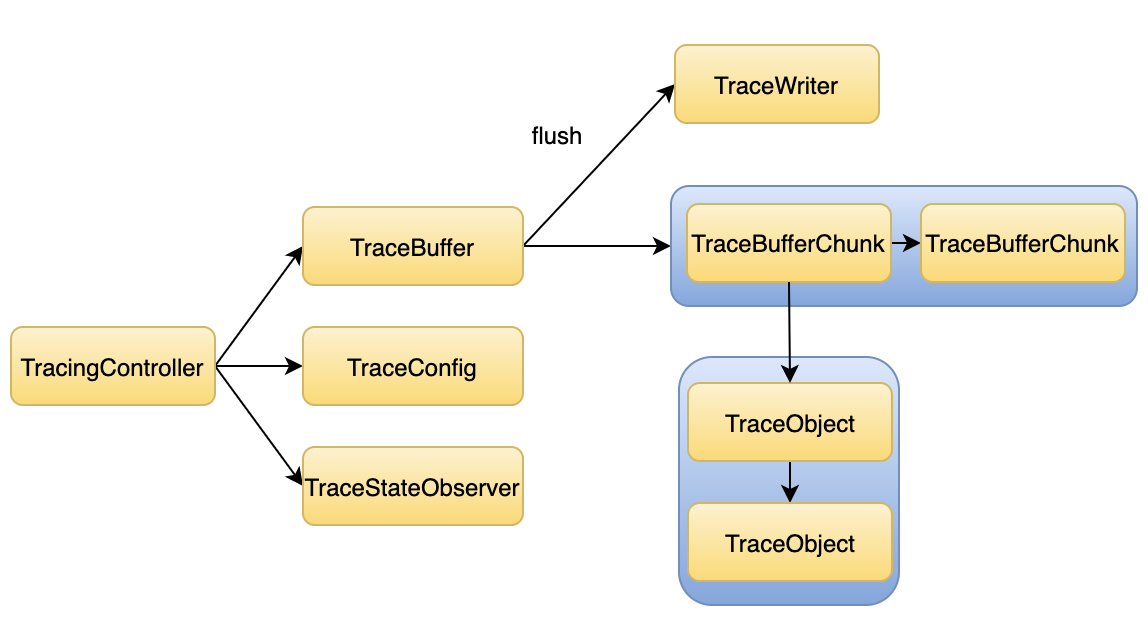 了解了 V8 的 trace 架构后,我们接下来看 Node.js 基于这个架构做了哪些实现。
了解了 V8 的 trace 架构后,我们接下来看 Node.js 基于这个架构做了哪些实现。 2 Node.js 的实现
2.1 InternalTraceBuffer
InternalTraceBuffer 是 Node.js 实现用于封装 TraceBufferChunk 的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | class InternalTraceBuffer {
public:
InternalTraceBuffer(size_t max_chunks, uint32_t id, Agent* agent);
TraceObject* AddTraceEvent(uint64_t* handle);
TraceObject* GetEventByHandle(uint64_t handle);
void Flush(bool blocking);
bool IsFull() const {
return total_chunks_ == max_chunks_ && chunks_[total_chunks_ - 1]->IsFull();
}
private:
size_t max_chunks_;
Agent* agent_;
std::vector<std::unique_ptr<TraceBufferChunk>> chunks_;
size_t total_chunks_ = 0;
};
|
2.2 NodeTraceBuffer
NodeTraceBuffer 是基础 V8 的 TraceBuffer。用于管理数据的存储和消费。内部持有 InternalTraceBuffer,InternalTraceBuffer 内部的 TraceBufferChunk 用于真正的数据存储。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | class NodeTraceBuffer : public TraceBuffer {
public:
NodeTraceBuffer(size_t max_chunks, Agent* agent, uv_loop_t* tracing_loop);
TraceObject* AddTraceEvent(uint64_t* handle) override;
TraceObject* GetEventByHandle(uint64_t handle) override;
bool Flush() override;
static const size_t kBufferChunks = 1024;
private:
uv_loop_t* tracing_loop_;
uv_async_t flush_signal_;
std::atomic<InternalTraceBuffer*> current_buf_;
InternalTraceBuffer buffer1_;
InternalTraceBuffer buffer2_;
};
|
2.3 NodeTraceWriter
NodeTraceWriter 用于处理数据的消费,比如写入文件。NodeTraceWriter 没有继承 V8 的 TraceWriter,而是持有一个 TraceWriter 对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // AsyncTraceWriter 没有逻辑,可以忽略
class NodeTraceWriter : public AsyncTraceWriter {
public:
explicit NodeTraceWriter(const std::string& log_file_pattern);
// 写入 trace 数据,保存在内存
void AppendTraceEvent(TraceObject* trace_event) override;
// 刷数据到目的地,比如文件
void Flush(bool blocking) override;
private:
// 数据写入该文件
std::string log_file_pattern_;
std::ostringstream stream_;
// 持有一个 TraceWriter 对象,具体是一个 json writer,即按 json 格式写入数据
std::unique_ptr<TraceWriter> json_trace_writer_;
};
|
2.4 TracingController
TracingController 继承 v8 的 TracingController,实现的逻辑不多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | class TracingController : public v8::platform::tracing::TracingController {
public:
TracingController() : v8::platform::tracing::TracingController() {}
int64_t CurrentTimestampMicroseconds() override {
return uv_hrtime() / 1000;
}
void AddMetadataEvent(...) {
std::unique_ptr<TraceObject> trace_event(new TraceObject);
trace_event->Initialize(...);
Agent* node_agent = node::tracing::TraceEventHelper::GetAgent();
if (node_agent != nullptr)
node_agent->AddMetadataEvent(std::move(trace_event));
};
};
|
2.5 Agent
Agent 是 Node.js 中 trace 系统的核心对象,用于管理整个 trace 系统。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | class Agent {
public:
TracingController* GetTracingController() {
TracingController* controller = tracing_controller_.get();
return controller;
}
// 增加一个 writer
AgentWriterHandle AddClient(const std::set<std::string>& categories,
std::unique_ptr<AsyncTraceWriter> writer,
enum UseDefaultCategoryMode mode);
// 获取订阅的 category,Node.js 本身缓存了这个数据,不需要到 V8 获取
std::string GetEnabledCategories() const;
// 产生 trace 数据,通知所有 writer
void AppendTraceEvent(TraceObject* trace_event);
void AddMetadataEvent(std::unique_ptr<TraceObject> event);
// 刷数据到目的地,比如文件
void Flush(bool blocking);
// 创建一个管理 category 的 TraceConfig 对象,并把缓存的 category 写到 v8
TraceConfig* CreateTraceConfig() const;
private:
// 启动 agent,不是启动收集 trace 数据
void Start();
void StopTracing();
// 订阅/取消订阅 category
void Enable(int id, const std::set<std::string>& categories);
void Disable(int id, const std::set<std::string>& categories);
// 保存 category、writer 和 controller
std::unordered_map<int, std::multiset<std::string>> categories_;
std::unordered_map<int, std::unique_ptr<AsyncTraceWriter>> writers_;
std::unique_ptr<TracingController> tracing_controller_;
};
|
2.6 ScopedSuspendTracing
ScopedSuspendTracing 利用 RAII 机制实现 category 的刷新,控制 category 的开启和关闭。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | class Agent::ScopedSuspendTracing {
public:
ScopedSuspendTracing(TracingController* controller, Agent* agent,
bool do_suspend = true)
: controller_(controller), agent_(do_suspend ? agent : nullptr) {
if (do_suspend) {
controller->StopTracing();
}
}
~ScopedSuspendTracing() {
if (agent_ == nullptr) return;
TraceConfig* config = agent_->CreateTraceConfig();
if (config != nullptr) {
controller_->StartTracing(config);
}
}
private:
TracingController* controller_;
Agent* agent_;
};
|
2.7 NodeTraceStateObserver
NodeTraceStateObserver 是 trace 的观察者,是 v8 提供的机制,在开启 trace 的时候会被执行。比如 Node.js 实现的观察者。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | class NodeTraceStateObserver: public v8::TracingController::TraceStateObserver {
public:
//。trace 启动时被回调
inline void OnTraceEnabled() override {
// 省略部分代码
trace_process->SetString("arch", per_process::metadata.arch.c_str());
trace_process->SetString("platform", per_process::metadata.platform.c_str());
trace_process->BeginDictionary("release");
trace_process->SetString("name", per_process::metadata.release.name.c_str());
// 产生 trace 数据
TRACE_EVENT_METADATA1("__metadata", "node", "process", std::move(trace_process));
}
private:
v8::TracingController* controller_;
};
|
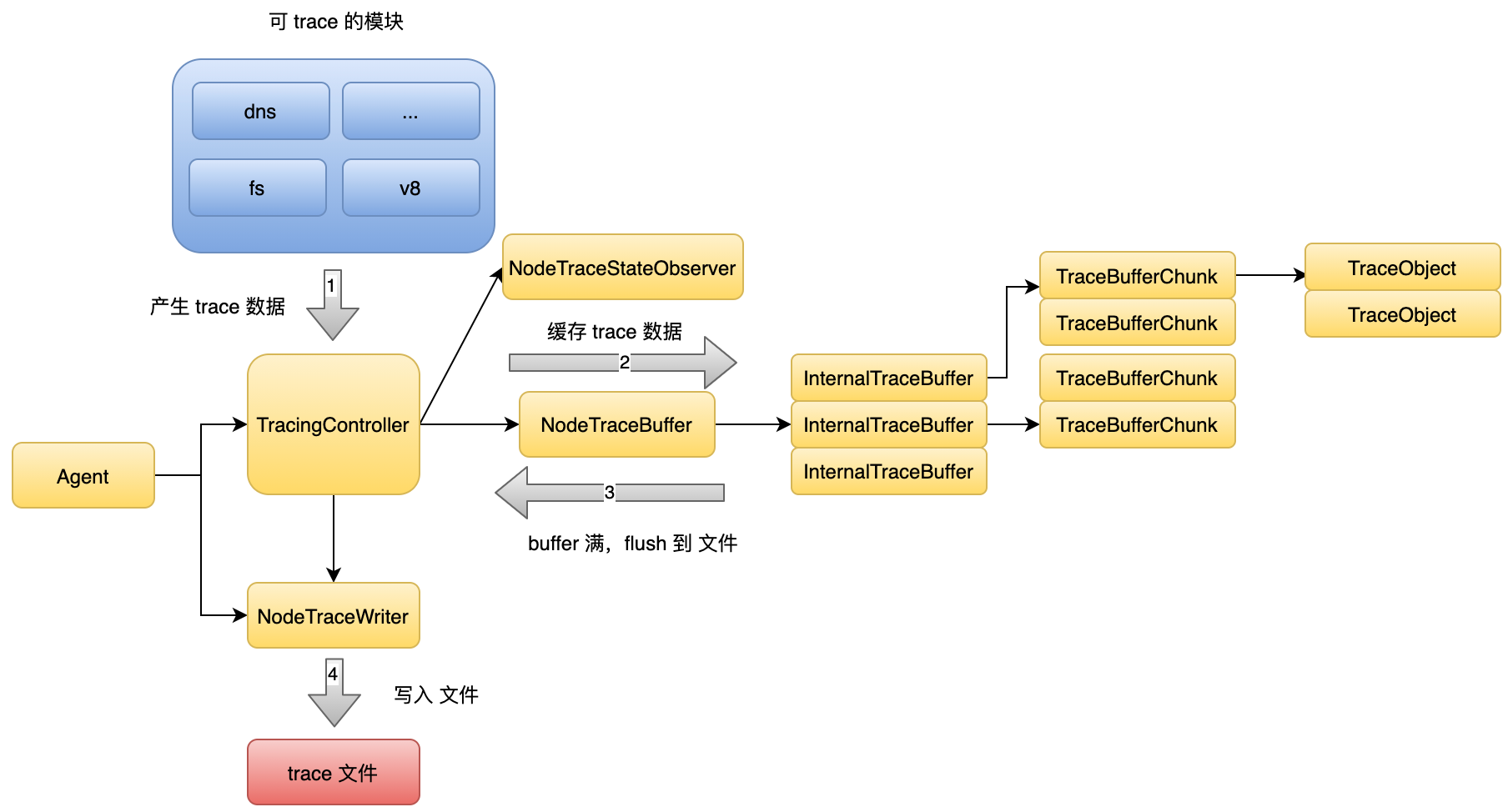
2.8 初始化 trace agent
再看一下 Node.js 初始化的过程中关于 trace agent 的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 | struct V8Platform {
bool initialized_ = false;
inline void Initialize(int thread_pool_size) {
// 创建一个 trace agent 对象
tracing_agent_ = std::make_unique<tracing::Agent>();
// 保存到某个地方,生产 trace 数据时使用
node::tracing::TraceEventHelper::SetAgent(tracing_agent_.get());
// 获取 agent 中的 controller,controller 负责管理 trace 数据的生产
node::tracing::TracingController* controller = tracing_agent_->GetTracingController();
// 创建一个 trace 观察者,在启动 trace 的时候被 V8 执行
trace_state_observer_ = std::make_unique<NodeTraceStateObserver>(controller);
// 保持到 controller 中
controller->AddTraceStateObserver(trace_state_observer_.get());
// tracing_file_writer_ 设置为默认值
tracing_file_writer_ = tracing_agent_->DefaultHandle();
// 通过命令行启动
if (!per_process::cli_options->trace_event_categories.empty()) {
StartTracingAgent();
}
}
inline tracing::AgentWriterHandle* GetTracingAgentWriter() {
return &tracing_file_writer_;
}
std::unique_ptr<NodeTraceStateObserver> trace_state_observer_;
std::unique_ptr<tracing::Agent> tracing_agent_;
tracing::AgentWriterHandle tracing_file_writer_;
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | inline void StartTracingAgent() {
if (tracing_file_writer_.IsDefaultHandle()) {
// 解析出命令后设置的需要 trace 的模块,如果设置了 --trace-events-enabled,则默认开启 v8,node,node.async_hooks
std::vector<std::string> categories = SplitString(per_process::cli_options->trace_event_categories, ',');
// 注册消费者 writer
tracing_file_writer_ = tracing_agent_->AddClient(
std::set<std::string>(std::make_move_iterator(categories.begin()),
std::make_move_iterator(categories.end())),
std::unique_ptr<tracing::AsyncTraceWriter>(
new tracing::NodeTraceWriter(
per_process::cli_options->trace_event_file_pattern)),
tracing::Agent::kUseDefaultCategories);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | AgentWriterHandle Agent::AddClient(
const std::set<std::string>& categories,
std::unique_ptr<AsyncTraceWriter> writer,
enum UseDefaultCategoryMode mode) {
// 启动 trace 子线程,如果还没有启动的话
Start();
const std::set<std::string>* use_categories = &categories;
int id = next_writer_id_++;
AsyncTraceWriter* raw = writer.get();
// 记录 writer 和 trace 的模块
writers_[id] = std::move(writer);
categories_[id] = { use_categories->begin(), use_categories->end() };
{
Mutex::ScopedLock lock(initialize_writer_mutex_);
// 记录待初始化的 writer
to_be_initialized_.insert(raw);
// 通知 trace 子线程
uv_async_send(&initialize_writer_async_);
while (to_be_initialized_.count(raw) > 0)
initialize_writer_condvar_.Wait(lock);
}
return AgentWriterHandle(this, id);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | Agent::Agent() : tracing_controller_(new TracingController()) {
tracing_controller_->Initialize(nullptr);
uv_loop_init(&tracing_loop_), 0;
// 注册 writer 时执行的回调
uv_async_init(&tracing_loop_, &initialize_writer_async_, [](uv_async_t* async) {
Agent* agent = ContainerOf(&Agent::initialize_writer_async_, async);
agent->InitializeWritersOnThread();
}), 0);
uv_unref(reinterpret_cast<uv_handle_t*>(&initialize_writer_async_));
}
void Agent::Start() {
if (started_)
return;
NodeTraceBuffer* trace_buffer_ = new NodeTraceBuffer(NodeTraceBuffer::kBufferChunks, this, &tracing_loop_);
tracing_controller_->Initialize(trace_buffer_);
uv_thread_create(&thread_, [](void* arg) {
Agent* agent = static_cast<Agent*>(arg);
uv_run(&agent->tracing_loop_, UV_RUN_DEFAULT);
}, this);
started_ = true;
}
|
| void Agent::InitializeWritersOnThread() {
Mutex::ScopedLock lock(initialize_writer_mutex_);
while (!to_be_initialized_.empty()) {
AsyncTraceWriter* head = *to_be_initialized_.begin();
head->InitializeOnThread(&tracing_loop_);
to_be_initialized_.erase(head);
}
initialize_writer_condvar_.Broadcast(lock);
}
|
| void NodeTraceWriter::InitializeOnThread(uv_loop_t* loop) {
tracing_loop_ = loop;
flush_signal_.data = this;
int err = uv_async_init(tracing_loop_, &flush_signal_, [](uv_async_t* signal) {
NodeTraceWriter* trace_writer = ContainerOf(&NodeTraceWriter::flush_signal_, signal);
trace_writer->FlushPrivate();
});
}
|
3 产生数据
Node.js 中 trace 数据通过两种方式产生,第一种方式是通过 Node.js C++ 层,第二种方式是在 JS 层通过 V8 提供的 trace C++ API。下面首先看一下第一种。
3.1 C++ 方式
接下来分析生产者。以同步打开文件 API 为例。下面是 open 函数的 trace 埋点。
| FS_SYNC_TRACE_BEGIN(open);
int result = SyncCall(env, args[4], &req_wrap_sync, "open",
uv_fs_open, *path, flags, mode);
FS_SYNC_TRACE_END(open);
|
| #define FS_SYNC_TRACE_BEGIN(syscall, ...) \
if (GET_TRACE_ENABLED) \
TRACE_EVENT_BEGIN(TRACING_CATEGORY_NODE2(fs, sync), TRACE_NAME(syscall), \
##__VA_ARGS__);
|
| // 判断是否订阅了当前模块的 trace
if (*node::tracing::TraceEventHelper::GetCategoryGroupEnabled("node,node.fs,node.fs.sync") != 0) {
// 通过 agent 的 controller 写入 trace 数据
controller->AddTraceEvent(...);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | const uint8_t* TracingController::GetCategoryGroupEnabled(
const char* category_group) {
// category 个数
size_t category_index = base::Acquire_Load(&g_category_index);
// 遍历判断是否开启了当前的 category
for (size_t i = 0; i < category_index; ++i) {
if (strcmp(g_category_groups[i], category_group) == 0) {
return &g_category_group_enabled[i];
}
}
// 如果没有看开启则追加到 category 列表
if (category_index < kMaxCategoryGroups) {
const char* new_group = base::Strdup(category_group);
g_category_groups[category_index] = new_group;
// 根据 traceConfig 更新开关
UpdateCategoryGroupEnabledFlag(category_index);
// 再次判断
category_group_enabled = &g_category_group_enabled[category_index];
// 更新 category 数量
base::Release_Store(&g_category_index, category_index + 1);
} else {
category_group_enabled =
&g_category_group_enabled[g_category_categories_exhausted];
}
return category_group_enabled;
}
|
| uint64_t TracingController::AddTraceEvent(...) {
int64_t now_us = CurrentTimestampMicroseconds();
return AddTraceEventWithTimestamp(...);
}
uint64_t TracingController::AddTraceEventWithTimestamp(...) {
TraceObject* trace_object = trace_buffer_->AddTraceEvent(&handle);
}
|
| TraceObject* NodeTraceBuffer::AddTraceEvent(uint64_t* handle) {
// buffer 是否已经满了,是则 flush
if (!TryLoadAvailableBuffer()) {
*handle = 0;
return nullptr;
}
// 否则缓存
return current_buf_.load()->AddTraceEvent(handle);
}
|
| bool NodeTraceBuffer::TryLoadAvailableBuffer() {
InternalTraceBuffer* prev_buf = current_buf_.load();
if (prev_buf->IsFull()) {
uv_async_send(&flush_signal_);
}
return true;
}
|
| NodeTraceBuffer::NodeTraceBuffer(size_t max_chunks,
Agent* agent, uv_loop_t* tracing_loop)
: tracing_loop_(tracing_loop),
buffer1_(max_chunks, 0, agent),
buffer2_(max_chunks, 1, agent) {
flush_signal_.data = this;
// 回调 NonBlockingFlushSignalCb
int err = uv_async_init(tracing_loop_, &flush_signal_,NonBlockingFlushSignalCb);
}
|
| void NodeTraceBuffer::NonBlockingFlushSignalCb(uv_async_t* signal) {
NodeTraceBuffer* buffer = static_cast<NodeTraceBuffer*>(signal->data);
if (buffer->buffer1_.IsFull() && !buffer->buffer1_.IsFlushing()) {
buffer->buffer1_.Flush(false);
}
if (buffer->buffer2_.IsFull() && !buffer->buffer2_.IsFlushing()) {
buffer->buffer2_.Flush(false);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | void InternalTraceBuffer::Flush(bool blocking) {
{
Mutex::ScopedLock scoped_lock(mutex_);
if (total_chunks_ > 0) {
flushing_ = true;
for (size_t i = 0; i < total_chunks_; ++i) {
auto& chunk = chunks_[i];
for (size_t j = 0; j < chunk->size(); ++j) {
TraceObject* trace_event = chunk->GetEventAt(j);
if (trace_event->name()) {
// 交给 agent 处理
agent_->AppendTraceEvent(trace_event);
}
}
}
total_chunks_ = 0;
flushing_ = false;
}
}
agent_->Flush(blocking);
}
|
| void Agent::AppendTraceEvent(TraceObject* trace_event) {
for (const auto& id_writer : writers_)
id_writer.second->AppendTraceEvent(trace_event);
}
void Agent::Flush(bool blocking) {
for (const auto& id_writer : writers_)
id_writer.second->Flush(blocking);
}
|
| void NodeTraceWriter::AppendTraceEvent(TraceObject* trace_event) {
Mutex::ScopedLock scoped_lock(stream_mutex_);
if (total_traces_ == 0) {
// 打开 trace 文件
OpenNewFileForStreaming();
json_trace_writer_.reset(TraceWriter::CreateJSONTraceWriter(stream_));
}
++total_traces_;
// 缓存数据
json_trace_writer_->AppendTraceEvent(trace_event);
}
|
| void NodeTraceWriter::Flush(bool blocking) {
int err = uv_async_send(&flush_signal_);
}
|
3.1 JS 方式
JS 方式是通过 v8 提供的 trace 函数。
| // binding.trace(phase, category, name, id, data)
SimpleInstallFunction(isolate(), extras_binding, "trace", Builtin::kTrace, 5, true);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | // Builtin::kTrace(phase, category, name, id, data)
BUILTIN(Trace) {
HandleScope handle_scope(isolate);
Handle<Object> phase_arg = args.atOrUndefined(isolate, 1);
Handle<Object> category = args.atOrUndefined(isolate, 2);
Handle<Object> name_arg = args.atOrUndefined(isolate, 3);
Handle<Object> id_arg = args.atOrUndefined(isolate, 4);
Handle<Object> data_arg = args.atOrUndefined(isolate, 5);
// 判断是否开启了该 category
const uint8_t* category_group_enabled = GetCategoryGroupEnabled(isolate, Handle<String>::cast(category));
// 没开启则不处理
if (!*category_group_enabled) return ReadOnlyRoots(isolate).false_value();
// 忽略细节处理
// 开启则处理
TRACE_EVENT_API_ADD_TRACE_EVENT(
phase, category_group_enabled, *name, tracing::kGlobalScope, id,
tracing::kNoId, num_args, &arg_name, &arg_type, &arg_value, flags);
return ReadOnlyRoots(isolate).true_value();
}
|
| #define TRACE_EVENT_API_ADD_TRACE_EVENT v8::internal::tracing::AddTraceEventImpl
static V8_INLINE uint64_t AddTraceEventImpl(...) {
v8::TracingController* controller = v8::internal::tracing::TraceEventHelper::GetTracingController();
return controller->AddTraceEvent(...);
}
|
两种产生数据的方式最终殊途同归,但是以上两种方式都是内置在 Node.js 内核的,用户侧无法使用,最近给 Node.js 社区提交了一个 pr(https://github.com/nodejs/node/pull/42462),把第二种方式通过 trace_events 模块导出来给用户使用。
4 收集数据
接下来介绍获取数据的逻辑。因为产生和消费 trace 数据会造成额外的开销,所以默认是不开启的,当我们需要收集这些数据的时候,首先需要主动订阅。一共有三种方式。
4.1 命令行方式
第一种是在启动 Node.js 时
| node --trace-event-categories v8 --trace-event-file-pattern '${pid}-${rotation}.log' server.js
|
4.2 通过 trace_events 模块
第二种方式就是动态开启。
| const trace_events = require('trace_events');
const categories = ['node.perf', 'node.async_hooks'];
const tracing = trace_events.createTracing({ categories });
tracing.enable();
// do something
tracing.disable();
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | function createTracing(options) {
return new Tracing(options.categories);
}
class Tracing {
constructor(categories) {
this[kHandle] = new CategorySet(categories);
this[kCategories] = categories;
this[kEnabled] = false;
}
enable() {
if (!this[kEnabled]) {
this[kEnabled] = true;
this[kHandle].enable();
}
}
}
|
| class NodeCategorySet : public BaseObject {
public:
static void New(const FunctionCallbackInfo<Value>& args);
static void Enable(const FunctionCallbackInfo<Value>& args);
static void Disable(const FunctionCallbackInfo<Value>& args);
private:
bool enabled_ = false;
const std::set<std::string> categories_; // 对象关联的 trace 模块
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13 | void NodeCategorySet::Enable(const FunctionCallbackInfo<Value>& args) {
NodeCategorySet* category_set;
ASSIGN_OR_RETURN_UNWRAP(&category_set, args.Holder());
const auto& categories = category_set->GetCategories();
// 非空并且没有启动则启动
if (!category_set->enabled_ && !categories.empty()) {
// 启动 trace agent,如果已经启动则直接返回
StartTracingAgent();
// 通过 writer 注册需要 trace 的模块
GetTracingAgentWriter()->Enable(categories);
category_set->enabled_ = true;
}
}
|
| void AgentWriterHandle::Enable(const std::set<std::string>& categories) {
if (agent_ != nullptr) agent_->Enable(id_, categories);
}
void Agent::Enable(int id, const std::set<std::string>& categories) {
ScopedSuspendTracing suspend(tracing_controller_.get(), this,
id != kDefaultHandleId);
categories_[id].insert(categories.begin(), categories.end());
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | void TracingController::StopTracing() {
bool expected = true;
// 判断是否已经开启了 trace,是则关闭(recording_ 为 false),否则直接 return
if (!recording_.compare_exchange_strong(expected, false)) {
return;
}
// 修改所有 category 为关闭哦状态
UpdateCategoryGroupEnabledFlags();
std::unordered_set<v8::TracingController::TraceStateObserver*> observers_copy;
{
base::MutexGuard lock(mutex_.get());
observers_copy = observers_;
}
// 通知 trace 观察者
for (auto o : observers_copy) {
o->OnTraceDisabled();
}
// 通知 writer 刷数据到目的地
{
base::MutexGuard lock(mutex_.get());
DCHECK(trace_buffer_);
trace_buffer_->Flush();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | void TracingController::UpdateCategoryGroupEnabledFlags() {
// g_category_index 记录了目前 category 数量
size_t category_index = base::Acquire_Load(&g_category_index);
// 清除所有 category 的 开启标记
for (size_t i = 0; i < category_index; i++) UpdateCategoryGroupEnabledFlag(i);
}
void TracingController::UpdateCategoryGroupEnabledFlag(size_t category_index) {
unsigned char enabled_flag = 0;
// g_category_groups 记录了所有 category 的名称
const char* category_group = g_category_groups[category_index];
/*
判断是否正在 trace 并且订阅了 category_group 对应的 category,
是则设置开启标记,开启了才能收集对应 category 的 trace 数据
*/
if (recording_.load(std::memory_order_acquire) &&
trace_config_->IsCategoryGroupEnabled(category_group)) {
enabled_flag |= ENABLED_FOR_RECORDING;
}
// 设置 category 的开启标记
base::Relaxed_Store(reinterpret_cast<base::Atomic8*>(
g_category_group_enabled + category_index),
enabled_flag);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | void TracingController::StartTracing(TraceConfig* trace_config) {
// 记录当前 trace 的 category
trace_config_.reset(trace_config);
std::unordered_set<v8::TracingController::TraceStateObserver*> observers_copy;
{
base::MutexGuard lock(mutex_.get());
// 设置开启 trace 标记
recording_.store(true, std::memory_order_release);
// 设置打开收集 category 数据的开关
UpdateCategoryGroupEnabledFlags();
observers_copy = observers_;
}
// 通知 trace 观察者
for (auto o : observers_copy) {
o->OnTraceEnabled();
}
}
|
4.3 通过 inspector 模块
第三种方式不仅可以动态开启,还能直接拿到 trace 数据,这种方式具体是通过 Inspector 协议。首先看一下如何使用这种方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | const { Session } = require('inspector');
const session = new Session();
session.connect();
function post(message, data) {
return new Promise((resolve, reject) => {
session.post(message, data, (err, result) => {
if (err)
reject(new Error(JSON.stringify(err)));
else
resolve(result);
});
});
}
async function test() {
session.on('NodeTracing.dataCollected', (data) => {
console.log(data.params.value);
});
session.on('NodeTracing.tracingComplete', () => {
console.log('done');
});
const { categories } = await post('NodeTracing.getCategories');
const traceConfig = { includedCategories: categories };
await post('NodeTracing.start', { traceConfig });
setTimeout(() => {
post('NodeTracing.stop');
}, 1000);
}
test();
|
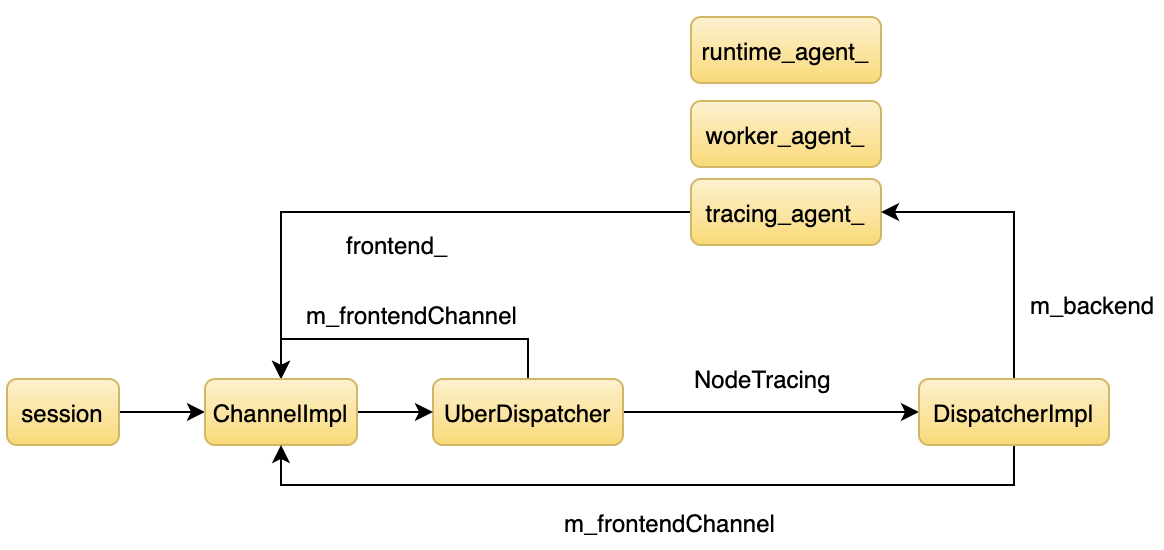 之前介绍过 Node.js Inspector 的架构,本文就不再具体展开介绍。简单来说,当我们通过 js 层的 session 发送命令时,代码流程从图的左边到右边,收集到数据时,代码流程从右往左回调 js 层。首先来看一下 NodeTracing.start。Node.js 的 Inspector 框架采用两级路由的机制,首先通过 NodeTracing 找到一级路由,在 inspetor 里叫 Domain,然后再通过 start 找到二级路由。 来看一下每个路由对应的函数。
之前介绍过 Node.js Inspector 的架构,本文就不再具体展开介绍。简单来说,当我们通过 js 层的 session 发送命令时,代码流程从图的左边到右边,收集到数据时,代码流程从右往左回调 js 层。首先来看一下 NodeTracing.start。Node.js 的 Inspector 框架采用两级路由的机制,首先通过 NodeTracing 找到一级路由,在 inspetor 里叫 Domain,然后再通过 start 找到二级路由。 来看一下每个路由对应的函数。 | m_dispatchMap["NodeTracing.getCategories"] = &DispatcherImpl::getCategories;
m_dispatchMap["NodeTracing.start"] = &DispatcherImpl::start;
m_dispatchMap["NodeTracing.stop"] = &DispatcherImpl::stop;
|
1
2
3
4
5
6
7
8
9
10
11
12 | void DispatcherImpl::start(int callId, const String& method, const ProtocolMessage& message, std::unique_ptr<DictionaryValue> requestMessageObject, ErrorSupport* errors)
{
protocol::DictionaryValue* object = DictionaryValue::cast(requestMessageObject->get("params"));
protocol::Value* traceConfigValue = object ? object->get("traceConfig") : nullptr;
std::unique_ptr<protocol::NodeTracing::TraceConfig> in_traceConfig = ValueConversions<protocol::NodeTracing::TraceConfig>::fromValue(traceConfigValue, errors);
std::unique_ptr<DispatcherBase::WeakPtr> weak = weakPtr();
DispatchResponse response = m_backend->start(std::move(in_traceConfig));
if (weak->get())
weak->get()->sendResponse(callId, response);
return;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | DispatchResponse TracingAgent::start(std::unique_ptr<protocol::NodeTracing::TraceConfig> traceConfig) {
std::set<std::string> categories_set;
protocol::Array<std::string>* categories = traceConfig->getIncludedCategories();
for (size_t i = 0; i < categories->length(); i++)
categories_set.insert(categories->get(i));
tracing::AgentWriterHandle* writer = GetTracingAgentWriter();
if (writer != nullptr) {
trace_writer_ =
writer->agent()->AddClient(categories_set,
std::make_unique<InspectorTraceWriter>(
frontend_object_id_, main_thread_),
tracing::Agent::kIgnoreDefaultCategories);
}
return DispatchResponse::OK();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | void AppendTraceEvent(
v8::platform::tracing::TraceObject* trace_event) override {
if (!json_writer_)
json_writer_.reset(TraceWriter::CreateJSONTraceWriter(stream_, "value"));
json_writer_->AppendTraceEvent(trace_event);
}
void Flush(bool) override {
if (!json_writer_)
return;
json_writer_.reset();
std::ostringstream result(
"{\"method\":\"NodeTracing.dataCollected\",\"params\":",
std::ostringstream::ate);
result << stream_.str();
result << "}";
main_thread_->Post(std::make_unique<SendMessageRequest>(frontend_object_id_,
result.str()));
stream_.str("");
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13 | void Call(MainThreadInterface* thread) override {
DeletableFrontendWrapper* frontend_wrapper = static_cast<DeletableFrontendWrapper*>(thread->GetObjectIfExists(object_id_));
if (frontend_wrapper == nullptr) return;
auto frontend = frontend_wrapper->get();
if (frontend != nullptr) {
frontend->sendRawJSONNotification(message_);
}
}
void Frontend::sendRawJSONNotification(String notification)
{
m_frontendChannel->sendProtocolNotification(InternalRawNotification::fromJSON(std::move(notification)));
}
|
| DispatchResponse TracingAgent::stop() {
trace_writer_.reset();
frontend_->tracingComplete();
return DispatchResponse::OK();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | void AgentWriterHandle::reset() {
if (agent_ != nullptr)
agent_->Disconnect(id_);
agent_ = nullptr;
}
void Agent::Disconnect(int client) {
if (client == kDefaultHandleId) return;
{
Mutex::ScopedLock lock(initialize_writer_mutex_);
to_be_initialized_.erase(writers_[client].get());
}
ScopedSuspendTracing suspend(tracing_controller_.get(), this);
writers_.erase(client);
categories_.erase(client);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13 | ScopedSuspendTracing(TracingController* controller, Agent* agent,
bool do_suspend = true)
: controller_(controller), agent_(do_suspend ? agent : nullptr) {
if (do_suspend) {
CHECK(agent_->started_);
controller->StopTracing();
}
}
void TracingController::StopTracing() {
base::MutexGuard lock(mutex_.get());
trace_buffer_->Flush();
}
|
| void Frontend::tracingComplete()
{
if (!m_frontendChannel)
return;
m_frontendChannel->sendProtocolNotification(InternalResponse::createNotification("NodeTracing.tracingComplete"));
}
|