流是对生产数据和消费数据过程的抽象,流本身不生产和消费数据,它只是定义了数据处理的流程。可读流是对数据源流向其它地方的过程抽象,属于生产者,可读流是对数据流向某一目的地的过程的抽象。Node.js中的流分为可读、可写、可读写、转换流。下面我先看一下流的基类。
21.1 流基类和流通用逻辑
| const EE = require('events');
const util = require('util');
// 流的基类
function Stream() {
EE.call(this);
}
// 继承事件订阅分发的能力
util.inherits(Stream, EE);
|
流的基类只提供了一个函数就是pipe。用于实现管道化。管道化是对数据从一个地方流向另一个地方的抽象。这个方法代码比较多,分开说。
21.1.1处理数据事件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | // 数据源对象
var source = this;
// 监听data事件,可读流有数据的时候,会触发data事件
source.on('data', ondata);
function ondata(chunk) {
// 源流有数据到达,并且目的流可写
if (dest.writable) {
/*
目的流过载并且源流实现了pause方法,
那就暂停可读流的读取操作,等待目的流触发drain事件
*/
if (false === dest.write(chunk) && source.pause) {
source.pause();
}
}
}
// 监听drain事件,目的流可以消费数据了就会触发该事件
dest.on('drain', ondrain);
function ondrain() {
// 目的流可继续写了,并且可读流可读,切换成自动读取模式
if (source.readable && source.resume) {
source.resume();
}
}
|
这是管道化时流控实现的地方,主要是利用了write返回值和drain事件。
21.1.2流关闭/结束处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | /*
1 dest._isStdio是true表示目的流是标准输出或标准错误(见
process/stdio.js),
2 配置的end字段代表可读流触发end或close事件时,是否自动关闭可写
流,默认是自动关闭。如果配置了end是false,则可读流这两个事件触发
时,我们需要自己关闭可写流。
3 我们看到可读流的error事件触发时,可写流是不会被自动关闭的,需要我
们自己监听可读流的error事件,然后手动关闭可写流。所以if的判断意思
是不是标准输出或标准错误流,并且没有配置end是false的时候,会自动
关闭可写流。而标准输出和标准错误流是在进程退出的时候才被关闭的。
*/
if (!dest._isStdio && (!options || options.end !== false)) {
// 源流没有数据可读了,执行end回调
source.on('end', onend);
// 源流关闭了,执行close回调
source.on('close', onclose);
}
var didOnEnd = false;
function onend() {
if (didOnEnd) return;
didOnEnd = true;
// 执行目的流的end,说明写数据完毕
dest.end();
}
function onclose() {
if (didOnEnd) return;
didOnEnd = true;
// 销毁目的流
if (typeof dest.destroy === 'function') dest.destroy();
}
|
上面是可读源流结束或关闭后,如何处理可写流的逻辑。默认情况下,我们只需要监听可读流的error事件,然后执行可写流的关闭操作。
21.1.3 错误处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // 可读流或者可写流出错的时候都需要停止数据的处理
source.on('error', onerror);
dest.on('error', onerror);
// 可读流或者可写流触发error事件时的处理逻辑
function onerror(er) {
// 出错了,清除注册的事件,包括正在执行的onerror函数
cleanup();
/*
如果用户没有监听流的error事件,则抛出错误,
所以我们业务代码需要监听error事件
*/
if (EE.listenerCount(this, 'error') === 0) {
throw er; // Unhandled stream error in pipe.
}
}
|
在error事件的处理函数中,通过cleanup函数清除了Node.js本身注册的error事件,所以这时候如果用户没有注册error事件,则error事件的处理函数个数为0,,所以我们需要注册error事件。下面我们再分析cleanup函数的逻辑。
21.1.4 清除注册的事件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 | // 保证源流关闭、数据读完、目的流关闭时清除注册的事件
source.on('end', cleanup);
source.on('close', cleanup);
dest.on('close', cleanup);
// 清除所有可能会绑定的事件,如果没有绑定,执行清除也是无害的
function cleanup() {
source.removeListener('data', ondata);
dest.removeListener('drain', ondrain);
source.removeListener('end', onend);
source.removeListener('close', onclose);
source.removeListener('error', onerror);
dest.removeListener('error', onerror);
source.removeListener('end', cleanup);
source.removeListener('close', cleanup);
dest.removeListener('close', cleanup);
}
// 触发目的流的pipe事件
dest.emit('pipe', source);
// 支持连续的管道化A.pipe(B).pipe(C)
return dest;
|
21.1.5 流的阈值
通过getHighWaterMark(lib\internal\streams\state.js)函数可以计算出流的阈值,阈值用于控制用户读写数据的速度。我们看看这个函数的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | function getHighWaterMark(state, options, duplexKey, isDuplex) { // 用户定义的阈值
let hwm = options.highWaterMark;
// 用户定义了,则校验是否合法
if (hwm != null) {
if (typeof hwm !== 'number' || !(hwm >= 0))
throw new errors.TypeError('ERR_INVALID_OPT_VALUE',
'highWaterMark',
hwm);
return Math.floor(hwm);
} else if (isDuplex) {
// 用户没有定义公共的阈值,即读写流公用的阈值
// 用户是否定义了流单独的阈值,比如读流的阈值或者写流的阈值
hwm = options[duplexKey];
// 用户有定义
if (hwm != null) {
if (typeof hwm !== 'number' || !(hwm >= 0))
throw new errors.TypeError('ERR_INVALID_OPT_VALUE',
duplexKey,
hwm);
return Math.floor(hwm);
}
}
// 默认值,对象是16个,buffer是16KB
return state.objectMode ? 16 : 16 * 1024;
}
|
getHighWaterMark函数逻辑如下
1 用户定义了合法的阈值,则取用户定义的(可读流、可写流、双向流)。
2 如果是双向流,并且用户没有可读流可写流共享的定义阈值,根据当前是可读流还是可写流,判断用户是否设置对应流的阈值。有则取用户设置的值作为阈值。
3 如果不满足1,2,则返回默认值。
21.1.6 销毁流
通过调用destroy函数可以销毁一个流,包括可读流和可写流。并且可以实现_ destroy函数自定义销毁的行为。我们看看可写流的destroy函数定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47 | function destroy(err, cb) {
// 读流、写流、双向流
const readableDestroyed = this._readableState &&
this._readableState.destroyed;
const writableDestroyed = this._writableState &&
this._writableState.destroyed;
// 流是否已经销毁,是则直接执行回调
if (readableDestroyed || writableDestroyed) {
// 传了cb,则执行,可选地传入err,用户定义的err
if (cb) {
cb(err);
} else if (err &&
(!this._writableState ||
!this._writableState.errorEmitted)) {
/*
传了err,是读流或者没有触发过error事件的写流,
则触发error事件
*/
process.nextTick(emitErrorNT, this, err);
}
return this;
}
// 还没有销毁则开始销毁流程
if (this._readableState) {
this._readableState.destroyed = true;
}
if (this._writableState) {
this._writableState.destroyed = true;
}
// 用户可以自定义_destroy函数
this._destroy(err || null, (err) => {
// 没有cb但是有error,则触发error事件
if (!cb && err) {
process.nextTick(emitErrorNT, this, err);
// 可写流则标记已经触发过error事件
if (this._writableState) {
this._writableState.errorEmitted = true;
}
} else if (cb) { // 有cb或者没有err
cb(err);
}
});
return this;
}
|
destroy函数销毁流的通用逻辑。其中_destroy函数不同的流不一样,下面分别是可读流和可写流的实现。 1 可读流
| Readable.prototype._destroy = function(err, cb) {
this.push(null);
cb(err);
};
|
2 可写流
| Writable.prototype._destroy = function(err, cb) {
this.end();
cb(err);
};
|
21.2 可读流
Node.js中可读流有两种工作模式:流式和暂停式,流式就是有数据的时候就会触发回调,并且把数据传给回调,暂停式就是需要用户自己手动执行读取的操作。我们通过源码去了解一下可读流实现的一些逻辑。因为实现的代码比较多,逻辑也比较绕,本文只分析一些主要的逻辑。我们先看一下ReadableState,这个对象是表示可读流的一些状态和属性的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 | function ReadableState(options, stream) {
options = options || {};
// 是否是双向流
var isDuplex = stream instanceof Stream.Duplex;
// 数据模式
this.objectMode = !!options.objectMode;
// 双向流的时候,设置读端的模式
if (isDuplex)
this.objectMode = this.objectMode ||
!!options.readableObjectMode;
// 读到highWaterMark个字节则停止,对象模式的话则是16个对象
this.highWaterMark = getHighWaterMark(this,
options, 'readableHighWaterMark',
isDuplex);
// 存储数据的缓冲区
this.buffer = new BufferList();
// 可读数据的长度
this.length = 0;
// 管道的目的源和个数
this.pipes = null;
this.pipesCount = 0;
// 工作模式
this.flowing = null;
// 流是否已经结束
this.ended = false;
// 是否触发过end事件了
this.endEmitted = false;
// 是否正在读取数据
this.reading = false;
// 是否同步执行事件
this.sync = true;
// 是否需要触发readable事件
this.needReadable = false;
// 是否触发了readable事件
this.emittedReadable = false;
// 是否监听了readable事件
this.readableListening = false;
// 是否正在执行resume的过程
this.resumeScheduled = false;
// 流是否已销毁
this.destroyed = false;
// 数据编码格式
this.defaultEncoding = options.defaultEncoding || 'utf8';
/*
在管道化中,有多少个写者已经达到阈值,
需要等待触发drain事件,awaitDrain记录达到阈值的写者个数
*/
this.awaitDrain = 0;
// 执行maybeReadMore函数的时候,设置为true
this.readingMore = false;
this.decoder = null;
this.encoding = null;
// 编码解码器
if (options.encoding) {
if (!StringDecoder)
StringDecoder = require('string_decoder').StringDecoder;
this.decoder = new StringDecoder(options.encoding);
this.encoding = options.encoding;
}
}
|
ReadableState里包含了一大堆字段,我们可以先不管它,等待用到的时候,再回头看。接着我们开始看可读流的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | function Readable(options) {
if (!(this instanceof Readable))
return new Readable(options);
this._readableState = new ReadableState(options, this);
// 可读
this.readable = true;
// 用户实现的两个函数
if (options) {
if (typeof options.read === 'function')
this._read = options.read;
if (typeof options.destroy === 'function')
this._destroy = options.destroy;
}
// 初始化父类
Stream.call(this);
}
|
上面的逻辑不多,需要关注的是read和destroy这两个函数,如果我们是直接使用Readable使用可读流,那在options里是必须传read函数的,destroy是可选的。如果我们是以继承的方式使用Readable,那必须实现_read函数。Node.js只是抽象了流的逻辑,具体的操作(比如可读流就是读取数据)是由用户自己实现的,因为读取操作是业务相关的。下面我们分析一下可读流的操作。
21.2.1 可读流从底层资源获取数据
对用户来说,可读流是用户获取数据的地方,但是对可读流来说,它提供数据给用户的前提是它自己有数据,所以可读流首先需要生产数据。生产数据的逻辑由_read函数实现。_read函数的逻辑大概是
| const data = getSomeData();
readableStream.push(data);
|
通过push函数,往可读流里写入数据,然后就可以为用户提供数据,我们看看push的实现,只列出主要逻辑。
Read
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44 | able.prototype.push = function(chunk, encoding) {
// 省略了编码处理的代码
return readableAddChunk(this,
chunk,
encoding,
false,
skipChunkCheck);
};
function readableAddChunk(stream,
chunk,
encoding,
addToFront,
skipChunkCheck) {
var state = stream._readableState;
// push null代表流结束
if (chunk === null) {
state.reading = false;
onEofChunk(stream, state);
} else {
addChunk(stream, state, chunk, false);
}
// 返回是否还可以读取更多数据
return needMoreData(state);
}
function addChunk(stream, state, chunk, addToFront) {
// 是流模式并且没有缓存的数据,则直接触发data事件
if (state.flowing && state.length === 0 && !state.sync) {
stream.emit('data', chunk);
} else {
// 否则先把数据缓存起来
state.length += state.objectMode ? 1 : chunk.length;
if (addToFront)
state.buffer.unshift(chunk);
else
state.buffer.push(chunk);
// 监听了readable事件则触发readable事件,通过read主动读取
if (state.needReadable)
emitReadable(stream);
}
// 继续读取数据,如果可以的话
maybeReadMore(stream, state);
}
|
总的来说,可读流首先要从某个地方获取数据,根据当前的工作模式,直接交付给用户,或者先缓存起来。可以的情况下,继续获取数据。
21.2.2 用户从可读流获取数据
用户可以通过read函数或者监听data事件来从可读流中获取数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | Readable.prototype.read = function(n) {
n = parseInt(n, 10);
var state = this._readableState;
// 计算可读的大小
n = howMuchToRead(n, state);
var ret;
// 需要读取的大于0,则取读取数据到ret返回
if (n > 0)
ret = fromList(n, state);
else
ret = null;
// 减去刚读取的长度
state.length -= n;
/*
如果缓存里没有数据或者读完后小于阈值了,
则可读流可以继续从底层资源里获取数据
*/
if (state.length === 0 ||
state.length - n < state.highWaterMark) {
this._read(state.highWaterMark);
}
// 触发data事件
if (ret !== null)
this.emit('data', ret);
return ret;
};
|
读取数据的操作就是计算缓存里有多少数据可以读,和用户需要的数据大小,取小的,然后返回给用户,并触发data事件。如果数据还没有达到阈值,则触发可读流从底层资源中获取数据。从而源源不断地生成数据。
21.3 可写流
可写流是对数据流向的抽象,用户调用可写流的接口,可写流负责控制数据的写入。流程如图21-1所示。
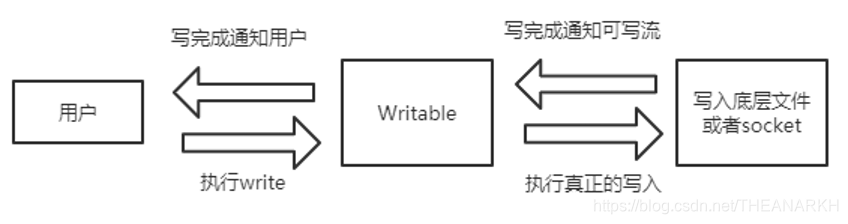
图21-1
下面是可写流的代码逻辑图如图21-2所示。
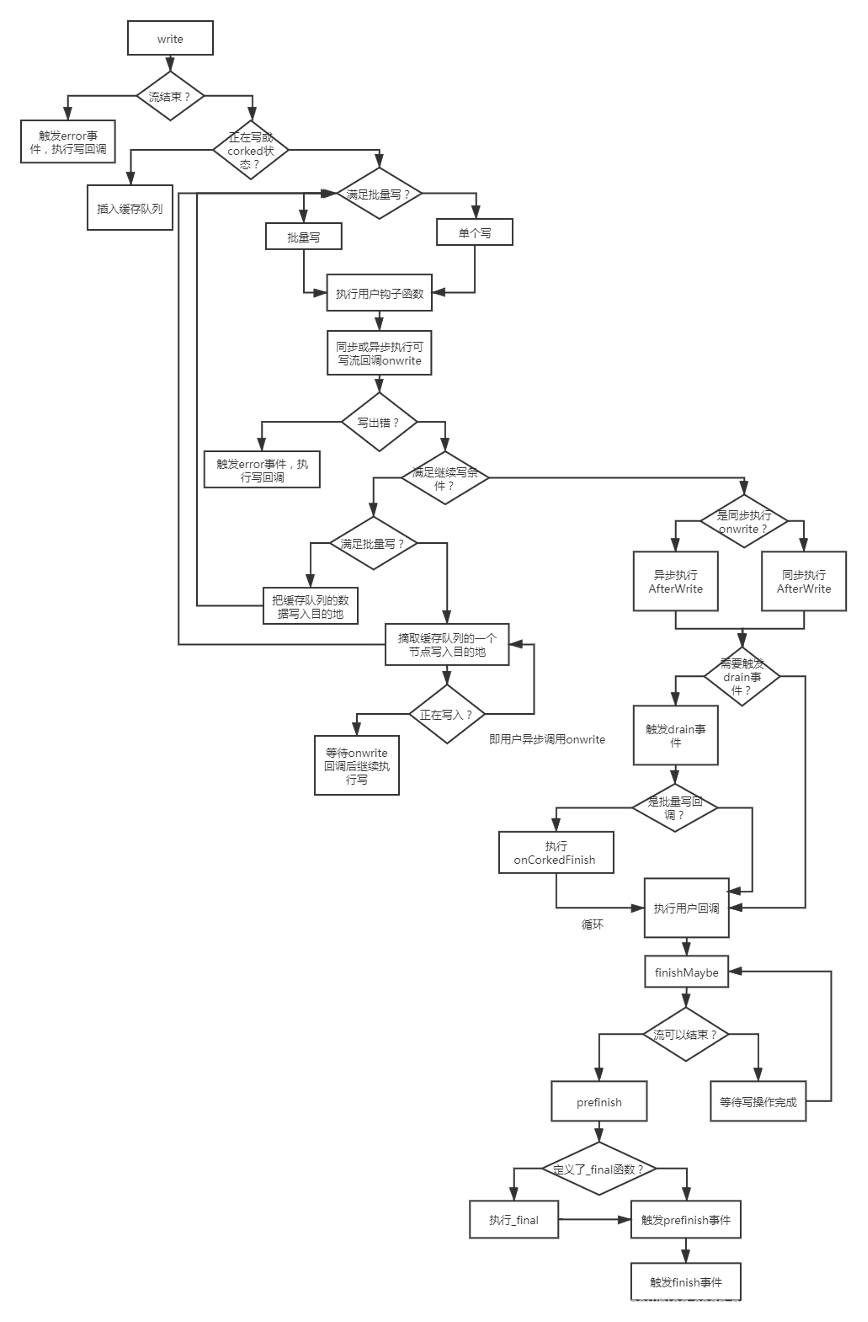
图21-2
我们看一下可写流的实现。
21.3.1 WritableState
WritableState是管理可写流配置的类。里面包含了非常的字段,具体含义我们会在后续分析的时候讲解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100 | function WritableState(options, stream) {
options = options || {};
// 是不是双向流
var isDuplex = stream instanceof Stream.Duplex;
// 数据模式
this.objectMode = !!options.objectMode;
/*
双向流的流默认共享objectMode配置,
用户可以自己配置成非共享,即读流和写流的数据模式独立
*/
if (isDuplex)
this.objectMode = this.objectMode ||
!!options.writableObjectMode;
/*
阈值,超过后说明需要暂停调用write,0代表每次调用write
的时候都返回false,用户等待drain事件触发后再执行write
*/
this.highWaterMark = getHighWaterMark(this,
options, 'writableHighWaterMark',isDuplex);
// 是否调用了_final函数
this.finalCalled = false;
// 是否需要触发drain事件,重新驱动生产者
this.needDrain = false;
// 正在执行end流程
this.ending = false;
// 是否执行过end函数
this.ended = false;
// 是否触发了finish事件
this.finished = false;
// 流是否被销毁了
this.destroyed = false;
var noDecode = options.decodeStrings === false;
// 是否需要decode流数据后在执行写(调用用户定义的_write)
this.decodeStrings = !noDecode;
// 编码类型
this.defaultEncoding = options.defaultEncoding || 'utf8';
// 待写入的数据长度或对象数
this.length = 0;
// 正在往底层写
this.writing = false;
// 加塞,缓存生产者的数据,停止往底层写入
this.corked = 0;
// 用户定义的_write或者_writev是同步还是异步调用可写流的回调函数onwrite
this.sync = true;
// 是否正在处理缓存的数据
this.bufferProcessing = false;
// 用户实现的钩子_write函数里需要执行的回调,告诉写流写完成了
this.onwrite = onwrite.bind(undefined, stream);
// 当前写操作对应的回调
this.writecb = null;
// 当前写操作的数据长度或对象数
this.writelen = 0;
// 缓存的数据链表头指针
this.bufferedRequest = null;
// 指向缓存的数据链表最后一个节点
this.lastBufferedRequest = null;
// 待执行的回调函数个数
this.pendingcb = 0;
// 是否已经触发过prefinished事件
this.prefinished = false;
// 是否已经触发过error事件
this.errorEmitted = false;
// count buffered requests
// 缓存的buffer数
this.bufferedRequestCount = 0;
/*
空闲的节点链表,当把缓存数据写入底层时,corkReq保数据的上下文(如
用户回调),因为这时候,缓存链表已经被清空,
this.corkedRequestsFree始终维护一个空闲节点,最多两个
*/
var corkReq = { next: null, entry: null, finish: undefined };
corkReq.finish = onCorkedFinish.bind(undefined, corkReq, this);
this.corkedRequestsFree = corkReq;
}
|
21.3.2 Writable
Writable是可写流的具体实现,我们可以直接使用Writable作为可写流来使用,也可以继承Writable实现自己的可写流。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | function Writable(options) {
this._writableState = new WritableState(options, this);
// 可写
this.writable = true;
// 支持用户自定义的钩子
if (options) {
if (typeof options.write === 'function')
this._write = options.write;
if (typeof options.writev === 'function')
this._writev = options.writev;
if (typeof options.destroy === 'function')
this._destroy = options.destroy;
if (typeof options.final === 'function')
this._final = options.final;
}
Stream.call(this);
}
|
可写流继承于流基类,提供几个钩子函数,用户可以自定义钩子函数实现自己的逻辑。如果用户是直接使用Writable类作为可写流,则options.write函数是必须传的,options.wirte函数控制数据往哪里写,并且通知可写流是否写完成了。如果用户是以继承Writable类的形式使用可写流,则_write函数是必须实现的,_write函数和options.write函数的作用是一样的。
21.3.3 数据写入
可写流提供write函数给用户实现数据的写入,写入有两种方式。一个是逐个写,一个是批量写,批量写是可选的,取决于用户的实现,如果用户直接使用Writable则需要传入writev,如果是继承方式使用Writable则实现_writev函数。我们先看一下write函数的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | Writable.prototype.write = function(chunk, encoding, cb) {
var state = this._writableState;
// 告诉用户是否还可以继续调用write
var ret = false;
// 数据格式
var isBuf = !state.objectMode && Stream._isUint8Array(chunk);
// 是否需要转成buffer格式
if (isBuf && Object.getPrototypeOf(chunk) !== Buffer.prototype) {
chunk = Stream._uint8ArrayToBuffer(chunk);
}
// 参数处理,传了数据和回调,没有传编码类型
if (typeof encoding === 'function') {
cb = encoding;
encoding = null;
}
// 是buffer类型则设置成buffer,否则如果没传则取默认编码
if (isBuf)
encoding = 'buffer';
else if (!encoding)
encoding = state.defaultEncoding;
if (typeof cb !== 'function')
cb = nop;
// 正在执行end,再执行write,报错
if (state.ending)
writeAfterEnd(this, cb);
else if (isBuf || validChunk(this, state, chunk, cb)) {
// 待执行的回调数加一,即cb
state.pendingcb++;
// 写入或缓存,见该函数
ret = writeOrBuffer(this, state, isBuf, chunk, encoding, cb);
}
/// 还能不能继续写
return ret;
};
|
write函数首先做了一些参数处理和数据转换,然后判断流是否已经结束了,如果流结束再执行写入,则会报错。如果流没有结束则执行写入或者缓存处理。最后通知用户是否还可以继续调用write写入数据(我们看到如果写入的数据比阈值大,可写流还是会执行写入操作,但是会返回false告诉用户些不要写入了,如果调用方继续写入的话,也是没会继续写入的,但是可能会导致写入端压力过大)。我们首先看一下writeAfterEnd的逻辑。然后再看writeOrBuffer。
| function writeAfterEnd(stream, cb) {
var er = new errors.Error('ERR_STREAM_WRITE_AFTER_END');
stream.emit('error', er);
process.nextTick(cb, er);
}
|
writeAfterEnd函数的逻辑比较简单,首先触发可写流的error事件,然后下一个tick的时候执行用户在调用write时传入的回调。接着我们看一下writeOrBuffer。writeOrBuffer函数会对数据进行缓存或者直接写入目的地(目的地可以是文件、socket、内存,取决于用户的实现),取决于当前可写流的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57 | function writeOrBuffer(stream, state, isBuf, chunk, encoding, cb) {
// 数据处理
if (!isBuf) {
var newChunk = decodeChunk(state, chunk, encoding);
if (chunk !== newChunk) {
isBuf = true;
encoding = 'buffer';
chunk = newChunk;
}
}
// 对象模式的算一个
var len = state.objectMode ? 1 : chunk.length;
// 更新待写入数据长度或对象个数
state.length += len;
// 待写入的长度是否超过了阈值
var ret = state.length < state.highWaterMark;
/*
超过了阈值,则设置需要等待drain事件标记,
这时候用户不应该再执行write,而是等待drain事件触发
*/
if (!ret)
state.needDrain = true;
// 如果正在写或者设置了阻塞则先缓存数据,否则直接写入
if (state.writing || state.corked) {
// 指向当前的尾节点
var last = state.lastBufferedRequest;
// 插入新的尾结点
state.lastBufferedRequest = {
chunk,
encoding,
isBuf,
callback: cb,
next: null
};
/*
之前还有节点的话,旧的尾节点的next指针指向新的尾节点,
形成链表
*/
if (last) {
last.next = state.lastBufferedRequest;
} else {
/*
指向buffer链表,bufferedRequest相等于头指针,
插入第一个buffer节点的时候执行到这
*/
state.bufferedRequest = state.lastBufferedRequest;
}
// 缓存的buffer个数加一
state.bufferedRequestCount += 1;
} else {
// 直接写入
doWrite(stream, state, false, len, chunk, encoding, cb);
}
// 返回是否还可以继续执行wirte,如果没有达到阈值则可以继续写
return ret;
}
|
writeOrBuffer函数主要的逻辑如下
1 更新待写入数据的长度,判断是否达到阈值,然后通知用户是否还可以执行write继续写入。
2 判断当前是否正在写入或者处于cork模式。是的话把数据缓存起来,否则执行写操作。
我们看一下缓存的逻辑和形成的数据结构。
缓存第一个节点时,如图21-3所示。
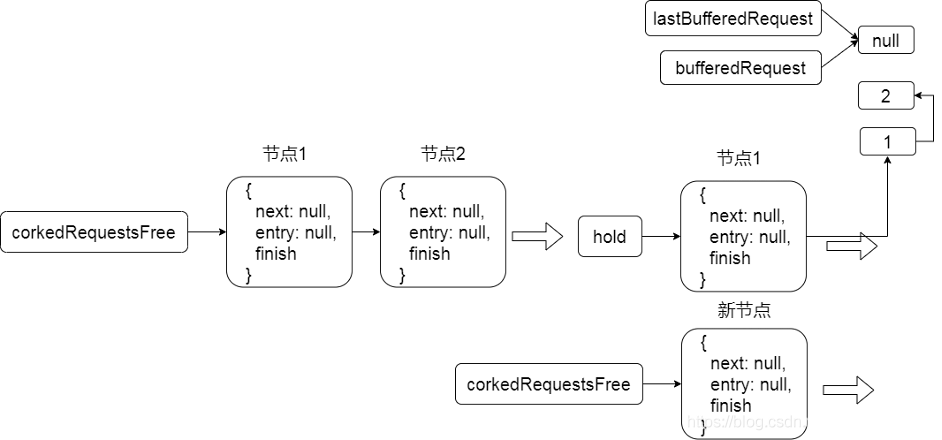
图21-3
缓存第二个节点时,如图21-4所示。

图21-4
缓存第三个节点时,如图21-5

图21-5
我们看到,函数的数据是以链表的形式管理的,其中bufferedRequest是链表头结点,lastBufferedRequest指向尾节点。假设当前可写流不处于写入或者cork状态。我们看一下写入的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | function doWrite(stream, state, writev, len, chunk, encoding, cb) {
// 本次写入的数据长度
state.writelen = len;
// 本次写完成后执行的回调
state.writecb = cb;
// 正在写入
state.writing = true;
// 假设用户定义的_writev或者_write函数是同步回调onwrite
state.sync = true;
if (writev)
// chunk为缓存待写入的buffer节点数组
stream._writev(chunk, state.onwrite);
else
// 执行用户定义的写函数,onwrite是Node.js定义的,在初始化的时候设置了该函数
stream._write(chunk, encoding, state.onwrite);
/*
如果用户是同步回调onwrite,则这句代码没有意义,
如果是异步回调onwrite,这句代码会在onwrite之前执行,
它标记用户是异步回调模式,在onwrite中需要判断回调模式,即sync的值
*/
state.sync = false;
}
|
doWrite函数记录了本次写入的上下文,比如长度,回调,然后设置正在写标记。最后执行写入。如果当前待写入的数据是缓存的数据并且用户实现了_writev函数,则调用_writev。否则调用_write。下面我们实现一个可写流的例子,把这里的逻辑串起来。
1
2
3
4
5
6
7
8
9
10
11
12
13 | const { Writable } = require('stream');
class DemoWritable extends Writable {
constructor() {
super();
this.data = null;
}
_write(chunk, encoding, cb) {
// 保存数据
this.data = this.data ? Buffer.concat([this.data, chunk]) : chunk;
// 执行回调告诉可写流写完成了,false代表写成功,true代表写失败
cb(null);
}
}
|
DemoWritable定义了数据流向的目的地,在用户调用write的时候,可写流会执行用户定义的_write,_write保存了数据,然后执行回调并传入参数,通知可写流数据写完成了,并通过参数标记写成功还是失败。这时候回到可写流侧。我们看到可写流设置的回调是onwrite,onwrite是在初始化可写流的时候设置的。
| this.onwrite = onwrite.bind(undefined, stream);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 | function onwrite(stream, er) {
var state = stream._writableState;
var sync = state.sync;
// 本次写完时执行的回调
var cb = state.writecb;
// 重置内部字段的值
// 写完了,重置回调,还有多少单位的数据没有写入,数据写完,重置本次待写入的数据数为0
state.writing = false;
state.writecb = null;
state.length -= state.writelen;
state.writelen = 0;
// 写出错
if (er)
onwriteError(stream, state, sync, er, cb);
else {
// Check if we're actually ready to finish, but don't emit yet
// 是否已经执行了end,并且数据也写完了(提交写操作和最后真正执行中间可能执行了end)
var finished = needFinish(state);
// 还没结束,并且没有设置阻塞标记,也不在处理buffer,并且有待处理的缓存数据,则进行写入
if (!finished &&
!state.corked &&
!state.bufferProcessing &&
state.bufferedRequest) {
clearBuffer(stream, state);
}
// 用户同步回调onwrite则Node.js异步执行用户回调
if (sync) {
process.nextTick(afterWrite, stream, state, finished, cb);
} else {
afterWrite(stream, state, finished, cb);
}
}
}
|
onwrite的逻辑如下
1 更新可写流的状态和数据
2 写出错则触发error事件和执行用户回调,写成功则判断是否满足继续执行写操作,是的话则继续写,否则执行用户回调。
我们看一下clearBuffer函数的逻辑,该逻辑主要是把缓存的数据写到目的地。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79 | function clearBuffer(stream, state) {
// 正在处理buffer
state.bufferProcessing = true;
// 指向头结点
var entry = state.bufferedRequest;
// 实现了_writev并且有两个以上的数据块,则批量写入,即一次把所有缓存的buffer都写入
if (stream._writev && entry && entry.next) {
// Fast case, write everything using _writev()
var l = state.bufferedRequestCount;
var buffer = new Array(l);
var holder = state.corkedRequestsFree;
// 指向待写入数据的链表
holder.entry = entry;
var count = 0;
// 数据是否全部都是buffer格式
var allBuffers = true;
// 把缓存的节点放到buffer数组中
while (entry) {
buffer[count] = entry;
if (!entry.isBuf)
allBuffers = false;
entry = entry.next;
count += 1;
}
buffer.allBuffers = allBuffers;
doWrite(stream, state, true, state.length, buffer, '', holder.finish);
// 待执行的cb加一,即holder.finish
state.pendingcb++;
// 清空缓存队列
state.lastBufferedRequest = null;
// 还有下一个节点则更新指针,下次使用
if (holder.next) {
state.corkedRequestsFree = holder.next;
holder.next = null;
} else {
// 没有下一个节点则恢复值,见初始化时的设置
var corkReq = { next: null, entry: null, finish: undefined };
corkReq.finish = onCorkedFinish.bind(undefined, corkReq, state);
state.corkedRequestsFree = corkReq;
}
state.bufferedRequestCount = 0;
} else {
// 慢慢写,即一个个buffer写,写完后等需要执行用户的cb,驱动下一个写
// Slow case, write chunks one-by-one
while (entry) {
var chunk = entry.chunk;
var encoding = entry.encoding;
var cb = entry.callback;
var len = state.objectMode ? 1 : chunk.length;
// 执行写入
doWrite(stream, state, false, len, chunk, encoding, cb);
entry = entry.next;
// 处理完一个,减一
state.bufferedRequestCount--;
/*
在onwrite里清除这个标记,onwrite依赖于用户执行,如果用户没调,
或者不是同步调,则退出,等待执行onwrite的时候再继续写
*/
if (state.writing) {
break;
}
}
// 写完了缓存的数据,则更新指针
if (entry === null)
state.lastBufferedRequest = null;
}
/*
更新缓存数据链表的头结点指向,
1 如果是批量写则entry为null
2 如果单个写,则可能还有值(如果用户是异步调用onwrite的话)
*/
state.bufferedRequest = entry;
// 本轮处理完毕(处理完一个或全部)
state.bufferProcessing = false;
}
|
clearBuffer的逻辑看起来非常多,但是逻辑并不算很复杂。主要分为两个分支。 1 用户实现了批量写函数,则一次把缓存的时候写入目的地。首先把缓存的数据(链表)全部收集起来,然后执行执行写入,并设置回调是finish函数。corkedRequestsFree字段指向一个节点数最少为一,最多为二的链表,用于保存批量写的数据的上下文。批量写时的数据结构图如图21-6和21-7所示(两种场景)。

图21-6
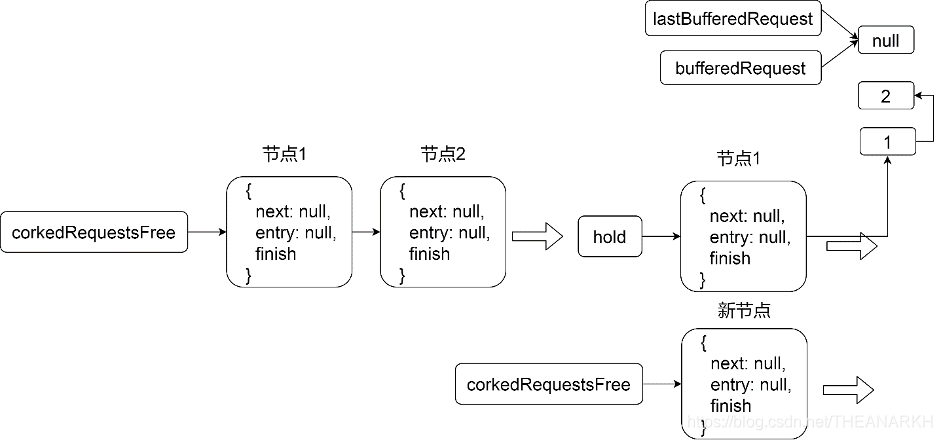
图21-7
corkedRequestsFree保证最少有一个节点,用于一次批量写,当使用完的时候,会最多保存两个空闲节点。我们看一下批量写成功后,回调函数onCorkedFinish的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | function onCorkedFinish(corkReq, state, err) {
// corkReq.entry指向当前处理的buffer链表头结点
var entry = corkReq.entry;
corkReq.entry = null;
// 遍历执行用户传入的回调回调
while (entry) {
var cb = entry.callback;
state.pendingcb--;
cb(err);
entry = entry.next;
}
// 回收corkReq,state.corkedRequestsFree这时候已经等于新的corkReq,指向刚用完的这个corkReq,共保存两个
state.corkedRequestsFree.next = corkReq;
}
|
onCorkedFinish首先从本次批量写的数据上下文取出回调,然后逐个执行。最后回收节点。corkedRequestsFree总是指向一个空闲节点,所以如果节点超过两个时,每次会把尾节点丢弃,如图21-8所示。
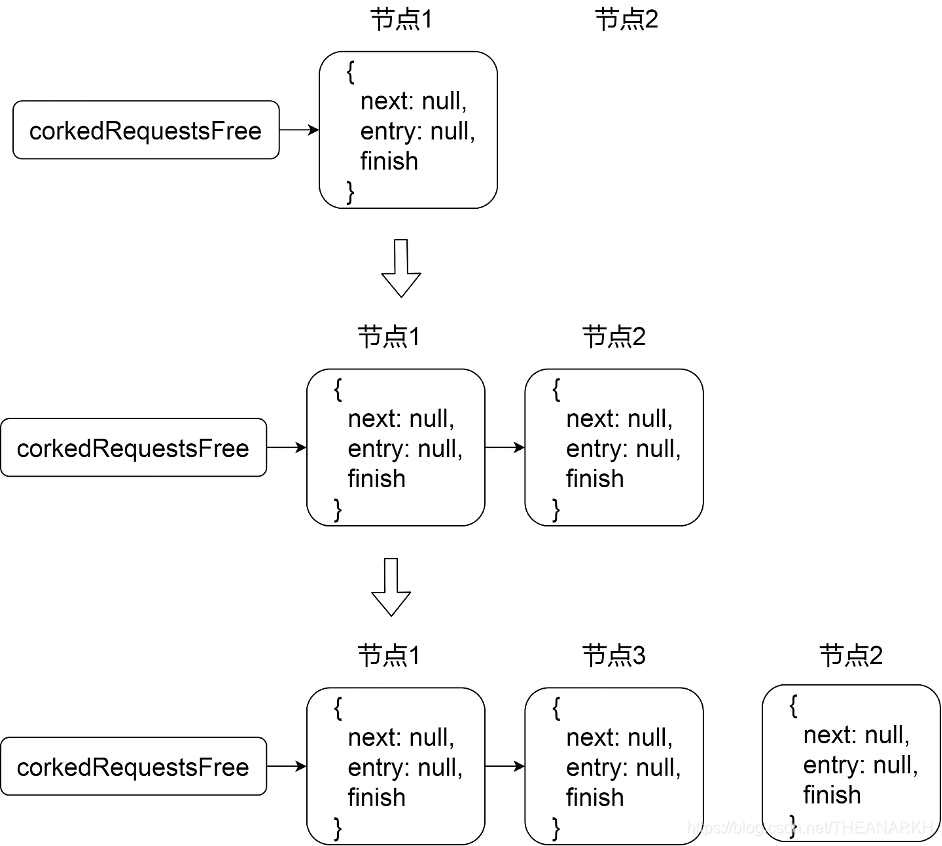
图21-8
2 接着我们看单个写的场景
单个写的时候,就是通过doWrite把数据逐个写到目的地,但是有一个地方需要注意的是,如果用户是异步执行可写流的回调onwrite(通过writing字段,因为onwrite会置writing为true,如果执行完doWrite,writing为false说明是异步回调),则写入一个数据后就不再执行doWrite进行写,而是需要等到onwrite回调被异步执行时,再执行下一次写,因为可写流是串行地执行写操作。 下面讲一下sync字段的作用。sync字段是用于标记执行用户自定义的write函数时,write函数是同步还是异步执行可写流的回调onwrite。主要用于控制是同步还是异步执行用户的回调。并且需要保证回调要按照定义的顺序执行。有两个地方涉及了这个逻辑,第一个是wirte的时候。我们看一下函数的调用关系,如图21-9所示。
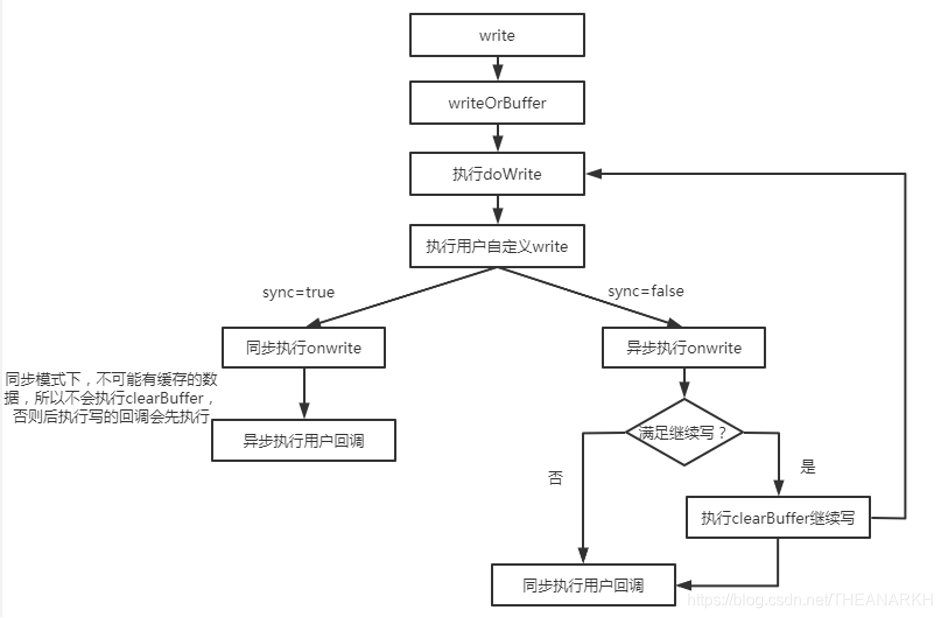
图21-9
如果用户是同步执行onwrite,则数据会被实时地消费,不存在缓存数据的情况,这时候Node.js异步并且有序地执行用户回调。如果用户连续两次调用了write写入数据,并且是以异步执行回调onwrite,则第一次执行onwrite的时候,会存在缓存的数据,这时候还没来得及执行用户回调,就会先发生第二次写入操作,同样,第二次写操作也是异步回调onwrite,所以接下来就会同步执行的用户回调。这样就保证了用户回调的顺序执行。第二种场景是uncork函数。我们看一下函数关系图,如图21-10所示。
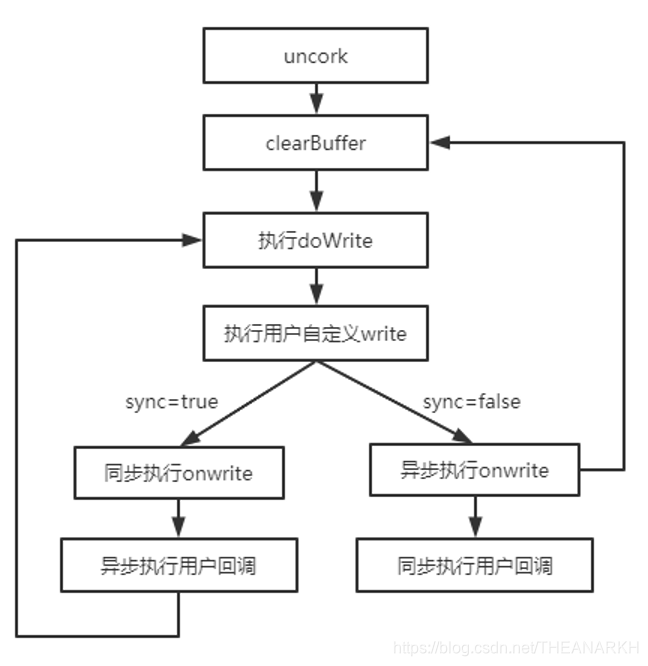
图21-10
在uncork的执行流程中,如果onwrite是被同步回调,则在onwrite中不会再次调用clearBuffer,因为这时候的bufferProcessing为true。这时候会先把用户的回调入队,然后再次执行doWrite发起下一次写操作。如果onwrite是被异步执行,在执行clearBuffer中,第一次执行doWrite完毕后,clearBuffer就会退出,并且这时候bufferProcessing为false。等到onwrite被回调的时候,再次执行clearBuffer,同样执行完doWrite的时候退出,等待异步回调,这时候用户回调被执行。 我们继续分析onwrite的代码,onwrite最后会调用afterWrite函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | function afterWrite(stream, state, finished, cb) {
// 还没结束,看是否需要触发drain事件
if (!finished)
onwriteDrain(stream, state);
// 准备执行用户回调,待执行的回调减一
state.pendingcb--;
cb();
finishMaybe(stream, state);
}
function onwriteDrain(stream, state) {
// 没有数据需要写了,并且流在阻塞中等待drain事件
if (state.length === 0 && state.needDrain) {
// 触发drain事件然后清空标记
state.needDrain = false;
stream.emit('drain');
}
}
|
afterWrite主要是判断是否需要触发drain事件,然后执行用户回调。最后判断流是否已经结束(在异步回调onwrite的情况下,用户调用回调之前,可能执行了end)。流结束的逻辑我们后面章节单独分析。
21.3.4 cork和uncork
cork和uncork类似tcp中的negal算法,主要用于累积数据后一次性写入目的地。而不是有一块就实时写入。比如在tcp中,每次发送一个字节,而协议头远远大于一字节,有效数据占比非常低。使用cork的时候最好同时提供writev实现,否则最后cork就没有意义,因为最终还是需要一块块的数据进行写入。我们看看cork的代码。
| Writable.prototype.cork = function() {
var state = this._writableState;
state.corked++;
};
|
cork的代码非常简单,这里使用一个整数而不是标记位,所以cork和uncork需要配对使用。我们看看uncork。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | Writable.prototype.uncork = function() {
var state = this._writableState;
if (state.corked) {
state.corked--;
/*
没有在进行写操作(如果进行写操作则在写操作完成的回调里会执行clearBuffer),
corked=0,
没有在处理缓存数据(writing为false已经说明),
有缓存的数据待处理
*/
if (!state.writing &&
!state.corked &&
!state.bufferProcessing &&
state.bufferedRequest)
clearBuffer(this, state);
}
};
|
21.3.5 流结束
流结束首先会把当前缓存的数据写入目的地,并且允许再执行额外的一次写操作,然后把可写流置为不可写和结束状态,并且触发一系列事件。下面是结束一个可写流的函数关系图。如图21-11所示。
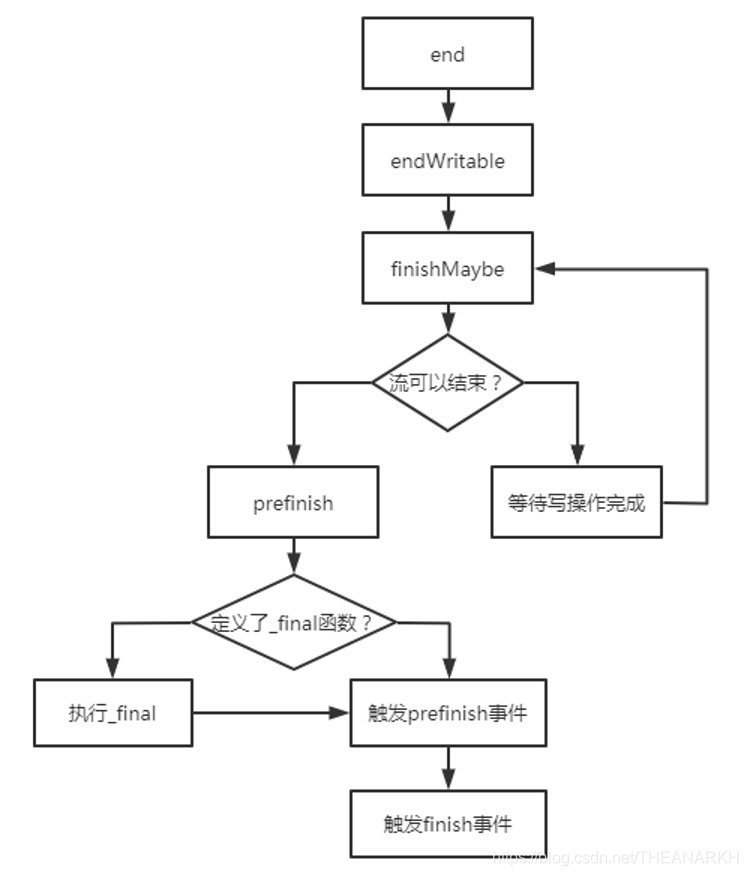
图21-11
通过end函数可以结束可写流,我们看看该函数的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 | Writable.prototype.end = function(chunk, encoding, cb) {
var state = this._writableState;
if (typeof chunk === 'function') {
cb = chunk;
chunk = null;
encoding = null;
} else if (typeof encoding === 'function') {
cb = encoding;
encoding = null;
}
// 最后一次写入的机会,可能直接写入,也可以会被缓存(正在写护着处于corked状态)
if (chunk !== null && chunk !== undefined)
this.write(chunk, encoding);
// 如果处于corked状态,则上面的写操作会被缓存,uncork和write保存可以对剩余数据执行写操作
if (state.corked) {
// 置1,为了uncork能正确执行,可以有机会写入缓存的数据
state.corked = 1;
this.uncork();
}
if (!state.ending)
endWritable(this, state, cb);
};
|
我们接着看endWritable函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | function endWritable(stream, state, cb) {
// 正在执行end函数
state.ending = true;
// 判断流是否可以结束了
finishMaybe(stream, state);
if (cb) {
// 已经触发了finish事件则下一个tick直接执行cb,否则等待finish事件
if (state.finished)
process.nextTick(cb);
else
stream.once('finish', cb);
}
// 流结束,流不可写
state.ended = true;
stream.writable = false;
}
|
endWritable函数标记流不可写并且处于结束状态。但是只是代表不能再调用write写数据了,之前缓存的数据需要被写完后才能真正地结束流。我们看finishMaybe函数的逻辑。该函数用于判断流是否可以结束。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | function needFinish(state) {
/*
执行了end函数则设置ending=true,
当前没有数据需要写入了,
也没有缓存的数据,
还没有触发finish事件,
没有正在进行写入
*/
return (state.ending &&
state.length === 0 &&
state.bufferedRequest === null &&
!state.finished &&
!state.writing);
}
// 每次写完成的时候也会调用该函数
function finishMaybe(stream, state) {
// 流是否可以结束
var need = needFinish(state);
// 是则先处理prefinish事件,否则先不管,等待写完成再调用该函数
if (need) {
prefinish(stream, state);
// 如果没有待执行的回调,则触发finish事件
if (state.pendingcb === 0) {
state.finished = true;
stream.emit('finish');
}
}
return need;
}
|
当可写流中所有数据和回调都执行了才能结束流,在结束流之前会先处理prefinish事件。 1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | function callFinal(stream, state) {
// 执行用户的final函数
stream._final((err) => {
// 执行了callFinal函数,cb减一
state.pendingcb--;
if (err) {
stream.emit('error', err);
}
// 执行prefinish
state.prefinished = true;
stream.emit('prefinish');
// 是否可以触发finish事件
finishMaybe(stream, state);
});
}
function prefinish(stream, state) {
// 还没触发prefinish并且没有执行finalcall
if (!state.prefinished && !state.finalCalled) {
// 用户传了final函数则,待执行回调数加一,即callFinal,否则直接触发prefinish
if (typeof stream._final === 'function') {
state.pendingcb++;
state.finalCalled = true;
process.nextTick(callFinal, stream, state);
} else {
state.prefinished = true;
stream.emit('prefinish');
}
}
}
|
如果用户定义了_final函数,则先执行该函数(这时候会阻止finish事件的触发),执行完后触发prefinish,再触发finish。如果没有定义_final,则直接触发prefinish事件。最后触发finish事件。
21.4 双向流
双向流是继承可读、可写的流。
| util.inherits(Duplex, Readable);
{
// 把可写流中存在,并且在可读流和Duplex里都不存在的方法加入到Duplex
const keys = Object.keys(Writable.prototype);
for (var v = 0; v < keys.length; v++) {
const method = keys[v];
if (!Duplex.prototype[method])
Duplex.prototype[method] = Writable.prototype[method];
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | function Duplex(options) {
if (!(this instanceof Duplex))
return new Duplex(options);
Readable.call(this, options);
Writable.call(this, options);
// 双向流默认可读
if (options && options.readable === false)
this.readable = false;
// 双向流默认可写
if (options && options.writable === false)
this.writable = false;
// 默认允许半开关
this.allowHalfOpen = true;
if (options && options.allowHalfOpen === false)
this.allowHalfOpen = false;
this.once('end', onend);
}
|
双向流继承了可读流和可写流的能力。双向流实现了以下功能
21.4.1 销毁
如果读写两端都销毁,则双向流销毁。
| Object.defineProperty(Duplex.prototype, 'destroyed', {
enumerable: false,
get() {
if (this._readableState === undefined ||
this._writableState === undefined) {
return false;
}
return this._readableState.destroyed && this._writableState.destroyed;
}
}
|
我们看如何销毁一个双向流。
| Duplex.prototype._destroy = function(err, cb) {
// 关闭读端
this.push(null);
// 关闭写端
this.end();
// 执行回调
process.nextTick(cb, err);
};
|
双向流还有一个特性是是否允许半开关,即可读或可写。onend是读端关闭时执行的函数。我们看看实现。
1
2
3
4
5
6
7
8
9
10
11
12
13 | // 关闭写流
function onend() {
// 允许半开关或写流已经结束则返回
if (this.allowHalfOpen || this._writableState.ended)
return;
// 下一个tick再关闭写流,执行完这段代码,用户还可以写
process.nextTick(onEndNT, this);
}
function onEndNT(self) {
// 调用写端的end函数
self.end();
}
|
当双向流允许半开关的情况下,可读流关闭时,可写流可以不关闭。