18-HTTP
HTTP模块实现了HTTP服务器和客户端的功能,是Node.js的核心模块,也是我们使用得最多的模块。本章我们来分析HTTP模块,从中我们可以学习到一个HTTP服务器和客户端是怎么实现的,以及HTTP协议本身的一些原理和优化。
18.1 HTTP解析器
HTTP解析器是HTTP模块的核心,不管是作为服务器处理请求还是客户端处理响应都需要使用HTTP解析器解析HTTP协议。新版Node.js使用了新的HTTP解析器llhttp。根据官方说明llhttp比旧版的http_parser在性能上有了非常大的提高。本节我们分析分析llhttp的基础原理和使用。HTTP解析器是一个非常复杂的状态机,在解析数据的过程中,会不断触发钩子函数。下面是llhttp支持的钩子函数。如果用户定义了对应的钩子,在解析的过程中就会被回调。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69 | // 开始解析HTTP协议
int llhttp__on_message_begin(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_message_begin, s);
return err;
}
// 解析出请求url时的回调,最后拿到一个url
int llhttp__on_url(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_url, s, p, endp - p);
return err;
}
// 解析出HTTP响应状态的回调
int llhttp__on_status(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_status, s, p, endp - p);
return err;
}
// 解析出头部键时的回调
int llhttp__on_header_field(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_header_field, s, p, endp - p);
return err;
}
// 解析出头部值时的回调
int llhttp__on_header_value(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_header_value, s, p, endp - p);
return err;
}
// 解析HTTP头完成时的回调
int llhttp__on_headers_complete(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_headers_complete, s);
return err;
}
// 解析完body的回调
int llhttp__on_message_complete(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_message_complete, s);
return err;
}
// 解析body时的回调
int llhttp__on_body(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_body, s, p, endp - p);
return err;
}
// 解析到一个chunk结构头时的回调
int llhttp__on_chunk_header(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_chunk_header, s);
return err;
}
// 解析完一个chunk时的回调
int llhttp__on_chunk_complete(llhttp_t* s, const char* p, const char* endp) {
int err;
CALLBACK_MAYBE(s, on_chunk_complete, s);
return err;
}
|
Node.js在node_http_parser.cc中对llhttp进行了封装。该模块导出了一个HTTPParser。
| Local<FunctionTemplate> t=env->NewFunctionTemplate(Parser::New);
t->InstanceTemplate()->SetInternalFieldCount(1);
t->SetClassName(FIXED_ONE_BYTE_STRING(env->isolate(),
"HTTPParser"));
target->Set(env->context(),
FIXED_ONE_BYTE_STRING(env->isolate(), "HTTPParser"),
t->GetFunction(env->context()).ToLocalChecked()).Check();
|
在Node.js中我们通过以下方式使用HTTPParser。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | const parser = new HTTPParser();
cleanParser(parser);
parser.onIncoming = null;
parser[kOnHeaders] = parserOnHeaders;
parser[kOnHeadersComplete] = parserOnHeadersComplete;
parser[kOnBody] = parserOnBody;
parser[kOnMessageComplete] = parserOnMessageComplete;
// 初始化HTTP解析器处理的报文类型,这里是响应报文
parser.initialize(HTTPParser.RESPONSE,
new HTTPClientAsyncResource('HTTPINCOMINGMESSAGE', req),
req.maxHeaderSize || 0,
req.insecureHTTPParser === undefined ?
isLenient() : req.insecureHTTPParser);
// 收到数据后传给解析器处理
const ret = parser.execute(data);
}
|
我们看一下initialize和execute的代码。Initialize函数用于初始化llhttp。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | static void Initialize(const FunctionCallbackInfo<Value>& args) {
Environment* env = Environment::GetCurrent(args);
bool lenient = args[3]->IsTrue();
uint64_t max_http_header_size = 0;
// 头部的最大大小
if (args.Length() > 2) {
max_http_header_size = args[2].As<Number>()->Value();
}
// 没有设置则取Node.js的默认值
if (max_http_header_size == 0) {
max_http_header_size=env->options()->max_http_header_size;
}
// 解析的报文类型
llhttp_type_t type =
static_cast<llhttp_type_t>(args[0].As<Int32>()->Value());
CHECK(type == HTTP_REQUEST || type == HTTP_RESPONSE);
Parser* parser;
ASSIGN_OR_RETURN_UNWRAP(&parser, args.Holder());
parser->Init(type, max_http_header_size, lenient);
}
|
Initialize做了一些预处理后调用Init。
1
2
3
4
5
6
7
8
9
10
11
12
13 | void Init(llhttp_type_t type, uint64_t max_http_header_size, bool lenient) {
// 初始化llhttp
llhttp_init(&parser_, type, &settings);
llhttp_set_lenient(&parser_, lenient);
header_nread_ = 0;
url_.Reset();
status_message_.Reset();
num_fields_ = 0;
num_values_ = 0;
have_flushed_ = false;
got_exception_ = false;
max_http_header_size_ = max_http_header_size;
}
|
Init做了一些字段的初始化,最重要的是调用了llhttp_init对llhttp进行了初始化,另外kOn开头的属性是钩子函数,由node_http_parser.cc中的回调,而node_http_parser.cc也会定义钩子函数,由llhttp回调,我们看一下node_http_parser.cc钩子函数的定义和实现。
1
2
3
4
5
6
7
8
9
10
11
12 | const llhttp_settings_t Parser::settings = {
Proxy<Call, &Parser::on_message_begin>::Raw,
Proxy<DataCall, &Parser::on_url>::Raw,
Proxy<DataCall, &Parser::on_status>::Raw,
Proxy<DataCall, &Parser::on_header_field>::Raw,
Proxy<DataCall, &Parser::on_header_value>::Raw,
Proxy<Call, &Parser::on_headers_complete>::Raw,
Proxy<DataCall, &Parser::on_body>::Raw,
Proxy<Call, &Parser::on_message_complete>::Raw,
Proxy<Call, &Parser::on_chunk_header>::Raw,
Proxy<Call, &Parser::on_chunk_complete>::Raw,
};
|
1 开始解析报文的回调
| // 开始解析报文,一个TCP连接可能会有多个报文
int on_message_begin() {
num_fields_ = num_values_ = 0;
url_.Reset();
status_message_.Reset();
return 0;
}
|
2 解析url时的回调
| int on_url(const char* at, size_t length) {
int rv = TrackHeader(length);
if (rv != 0) {
return rv;
}
url_.Update(at, length);
return 0;
}
|
3解析HTTP响应时的回调
| int on_status(const char* at, size_t length) {
int rv = TrackHeader(length);
if (rv != 0) {
return rv;
}
status_message_.Update(at, length);
return 0;
}
|
4解析到HTTP头的键时回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | int on_header_field(const char* at, size_t length) {
int rv = TrackHeader(length);
if (rv != 0) {
return rv;
}
// 相等说明键对值的解析是一一对应的
if (num_fields_ == num_values_) {
// start of new field name
// 键的数加一
num_fields_++;
// 超过阈值则先回调js消费掉
if (num_fields_ == kMaxHeaderFieldsCount) {
// ran out of space - flush to javascript land
Flush();
// 重新开始
num_fields_ = 1;
num_values_ = 0;
}
// 初始化
fields_[num_fields_ - 1].Reset();
}
// 保存键
fields_[num_fields_ - 1].Update(at, length);
return 0;
}
|
当解析的头部个数达到阈值时,Node.js会先通过Flush函数回调JS层保存当前的一些数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | void Flush() {
HandleScope scope(env()->isolate());
Local<Object> obj = object();
// JS层的钩子
Local<Value> cb = obj->Get(env()->context(), kOnHeaders).ToLocalChecked();
if (!cb->IsFunction())
return;
Local<Value> argv[2] = {
CreateHeaders(),
url_.ToString(env())
};
MaybeLocal<Value> r = MakeCallback(cb.As<Function>(),
arraysize(argv),
argv);
url_.Reset();
have_flushed_ = true;
}
Local<Array> CreateHeaders() {
// HTTP头的个数乘以2,因为一个头由键和值组成
Local<Value> headers_v[kMaxHeaderFieldsCount * 2];
// 保存键和值到HTTP头
for (size_t i = 0; i < num_values_; ++i) {
headers_v[i * 2] = fields_[i].ToString(env());
headers_v[i * 2 + 1] = values_[i].ToString(env());
}
return Array::New(env()->isolate(), headers_v, num_values_ * 2);
}
|
Flush会调用JS层的kOnHeaders钩子函数。
5解析到HTTP头的值时回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | int on_header_value(const char* at, size_t length) {
int rv = TrackHeader(length);
if (rv != 0) {
return rv;
}
/*
值的个数不等于键的个数说明正解析到键对应的值,即一一对应。
否则说明一个键存在多个值,则不更新值的个数,多个值累加到一个slot
*/
if (num_values_ != num_fields_) {
// start of new header value
num_values_++;
values_[num_values_ - 1].Reset();
}
CHECK_LT(num_values_, arraysize(values_));
CHECK_EQ(num_values_, num_fields_);
values_[num_values_ - 1].Update(at, length);
return 0;
}
|
6解析完HTTP头后的回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82 | int on_headers_complete() {
header_nread_ = 0;
enum on_headers_complete_arg_index {
A_VERSION_MAJOR = 0,
A_VERSION_MINOR,
A_HEADERS,
A_METHOD,
A_URL,
A_STATUS_CODE,
A_STATUS_MESSAGE,
A_UPGRADE,
A_SHOULD_KEEP_ALIVE,
A_MAX
};
Local<Value> argv[A_MAX];
Local<Object> obj = object();
Local<Value> cb = obj->Get(env()->context(),
kOnHeadersComplete).ToLocalChecked();
Local<Value> undefined = Undefined(env()->isolate());
for (size_t i = 0; i < arraysize(argv); i++)
argv[i] = undefined;
// 之前flush过,则继续flush到JS层,否则返回全部头给js
if (have_flushed_) {
// Slow case, flush remaining headers.
Flush();
} else {
// Fast case, pass headers and URL to JS land.
argv[A_HEADERS] = CreateHeaders();
if (parser_.type == HTTP_REQUEST)
argv[A_URL] = url_.ToString(env());
}
num_fields_ = 0;
num_values_ = 0;
// METHOD
if (parser_.type == HTTP_REQUEST) {
argv[A_METHOD] =
Uint32::NewFromUnsigned(env()->isolate(), parser_.method);
}
// STATUS
if (parser_.type == HTTP_RESPONSE) {
argv[A_STATUS_CODE] =
Integer::New(env()->isolate(), parser_.status_code);
argv[A_STATUS_MESSAGE] = status_message_.ToString(env());
}
// VERSION
argv[A_VERSION_MAJOR] = Integer::New(env()->isolate(), parser_.http_major);
argv[A_VERSION_MINOR] = Integer::New(env()->isolate(), parser_.http_minor);
bool should_keep_alive;
// 是否定义了keepalive头
should_keep_alive = llhttp_should_keep_alive(&parser_);
argv[A_SHOULD_KEEP_ALIVE] =
Boolean::New(env()->isolate(), should_keep_alive);
// 是否是升级协议
argv[A_UPGRADE] = Boolean::New(env()->isolate(), parser_.upgrade);
MaybeLocal<Value> head_response;
{
InternalCallbackScope callback_scope(
this, InternalCallbackScope::kSkipTaskQueues);
head_response = cb.As<Function>()->Call(
env()->context(), object(), arraysize(argv), argv);
}
int64_t val;
if (head_response.IsEmpty() || !head_response.ToLocalChecked()
->IntegerValue(env()->context())
.To(&val)) {
got_exception_ = true;
return -1;
}
return val;
}
|
on_headers_complete会执行JS层的kOnHeadersComplete钩子。
7 解析body时的回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | int on_body(const char* at, size_t length) {
EscapableHandleScope scope(env()->isolate());
Local<Object> obj = object();
Local<Value> cb = obj->Get(env()->context(), kOnBody).ToLocalChecked();
// We came from consumed stream
if (current_buffer_.IsEmpty()) {
// Make sure Buffer will be in parent HandleScope
current_buffer_ = scope.Escape(Buffer::Copy(
env()->isolate(),
current_buffer_data_,
current_buffer_len_).ToLocalChecked());
}
Local<Value> argv[3] = {
// 当前解析中的数据
current_buffer_,
// body开始的位置
Integer::NewFromUnsigned(env()->isolate(), at - current_buffer_data_),
// body当前长度
Integer::NewFromUnsigned(env()->isolate(), length)
};
MaybeLocal<Value> r = MakeCallback(cb.As<Function>(),
arraysize(argv),
argv);
return 0;
}
|
Node.js中并不是每次解析HTTP报文的时候就新建一个HTTP解析器,Node.js使用FreeList数据结构对HTTP解析器实例进行了管理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | class FreeList {
constructor(name, max, ctor) {
this.name = name;
// 构造函数
this.ctor = ctor;
// 节点的最大值
this.max = max;
// 实例列表
this.list = [];
}
// 分配一个实例
alloc() {
// 有空闲的则直接返回,否则新建一个
return this.list.length > 0 ?
this.list.pop() :
ReflectApply(this.ctor, this, arguments);
}
// 释放实例
free(obj) {
// 小于阈值则放到空闲列表,否则释放(调用方负责释放)
if (this.list.length < this.max) {
this.list.push(obj);
return true;
}
return false;
}
}
|
我们看一下在Node.js中对FreeList的使用。。
1
2
3
4
5
6
7
8
9
10
11
12
13 | const parsers = new FreeList('parsers', 1000, function parsersCb() {
const parser = new HTTPParser();
// 初始化字段
cleanParser(parser);
// 设置钩子
parser.onIncoming = null;
parser[kOnHeaders] = parserOnHeaders;
parser[kOnHeadersComplete] = parserOnHeadersComplete;
parser[kOnBody] = parserOnBody;
parser[kOnMessageComplete] = parserOnMessageComplete;
return parser;
});
|
HTTP解析器的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | var HTTPParser = process.binding('http_parser').HTTPParser;
var parser = new HTTPParser(HTTPParser.REQUEST);
const kOnHeaders = HTTPParser.kOnHeaders;
const kOnHeadersComplete = HTTPParser.kOnHeadersComplete;
const kOnBody = HTTPParser.kOnBody;
const kOnMessageComplete = HTTPParser.kOnMessageComplete;
const kOnExecute = HTTPParser.kOnExecute;
parser[kOnHeaders] = function(headers, url) {
console.log('kOnHeaders', headers.length, url);
}
parser[kOnHeadersComplete] = function(versionMajor, versionMinor, headers, method,
url, statusCode, statusMessage, upgrade, shouldKeepAlive) {
console.log('kOnHeadersComplete', headers);
}
parser[kOnBody] = function(b, start, len) {
console.log('kOnBody', b.slice(start).toString('utf-8'));
}
parser[kOnMessageComplete] = function() {
console.log('kOnMessageComplete');
}
parser[kOnExecute] = function() {
console.log('kOnExecute');
}
parser.execute(Buffer.from(
'GET / HTTP/1.1\r\n' +
'Host: http://localhost\r\n\r\n'
));
|
以上代码的输出
| kOnHeadersComplete [ 'Host', 'http://localhost' ]
kOnMessageComplete
|
我们看到只执行了kOnHeadersComplete和 kOnMessageComplete。那其它几个回调什么时候会执行呢?我们接着看。我们把输入改一下。
| parser.execute(Buffer.from(
'GET / HTTP/1.1\r\n' +
'Host: http://localhost\r\n' +
'content-length: 1\r\n\r\n'+
'1'
));
|
上面代码的输出
| kOnHeadersComplete [ 'Host', 'http://localhost', 'content-length', '1' ]
kOnBody 1
kOnMessageComplete
|
我们看到多了一个回调kOnBody,因为我们加了一个HTTP头content-length指示有body,所以HTTP解析器解析到body的时候就会回调kOnBody。那kOnHeaders什么时候会执行呢?我们继续修改代码。
| parser.execute(Buffer.from(
'GET / HTTP/1.1\r\n' +
'Host: http://localhost\r\n' +
'a: b\r\n'+
// 很多'a: b\r\n'+
'content-length: 1\r\n\r\n'+
'1'
));
|
以上代码的输出
| kOnHeaders 62 /
kOnHeaders 22
kOnHeadersComplete undefined
kOnBody 1
kOnMessageComplete
|
我们看到kOnHeaders被执行了,并且执行了两次。因为如果HTTP头的个数达到阈值,在解析HTTP头部的过程中,就先flush到JS层(如果多次达到阈值,则回调多次),并且在解析完所有HTTP头后,会在kOnHeadersComplet回调之前再次回调kOnHeaders(如果还有的话)。最后我们看一下kOnExecute如何触发。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40 | var HTTPParser = process.binding('http_parser').HTTPParser;
var parser = new HTTPParser(HTTPParser.REQUEST);
var net = require('net');
const kOnHeaders = HTTPParser.kOnHeaders;
const kOnHeadersComplete = HTTPParser.kOnHeadersComplete;
const kOnBody = HTTPParser.kOnBody;
const kOnMessageComplete = HTTPParser.kOnMessageComplete;
const kOnExecute = HTTPParser.kOnExecute;
parser[kOnHeaders] = function(headers, url) {
console.log('kOnHeaders', headers.length, url);
}
parser[kOnHeadersComplete] = function(versionMajor, versionMinor, headers, method,
url, statusCode, statusMessage, upgrade, shouldKeepAlive) {
console.log('kOnHeadersComplete', headers);
}
parser[kOnBody] = function(b, start, len) {
console.log('kOnBody', b.slice(start).toString('utf-8'));
}
parser[kOnMessageComplete] = function() {
console.log('kOnMessageComplete');
}
parser[kOnExecute] = function(a,b) {
console.log('kOnExecute,解析的字节数:',a);
}
// 启动一个服务器
net.createServer((socket) => {
parser.consume(socket._handle);
}).listen(80);
// 启动一个客户端
setTimeout(() => {
var socket = net.connect({port: 80});
socket.end('GET / HTTP/1.1\r\n' +
'Host: http://localhost\r\n' +
'content-length: 1\r\n\r\n'+
'1');
}, 1000);
|
我们需要调用parser.consume方法并且传入一个isStreamBase的流(stream_base.cc定义),才会触发kOnExecute。因为kOnExecute是在StreamBase流可读时触发的。
18.2 HTTP客户端
我们首先看一下使用Node.js作为客户端的例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | const data = querystring.stringify({
'msg': 'hi'
});
const options = {
hostname: 'your domain',
path: '/',
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': Buffer.byteLength(data)
}
};
const req = http.request(options, (res) => {
res.setEncoding('utf8');
res.on('data', (chunk) => {
console.log(`${chunk}`);
});
res.on('end', () => {
console.log('end');
});
});
req.on('error', (e) => {
console.error(`${e.message}`);
});
// 发送请求的数据
req.write(data);
// 设置请求结束
req.end();
|
我们看一下http.request的实现。
| function request(url, options, cb) {
return new ClientRequest(url, options, cb);
}
|
HTTP客户端通过_http_client.js的ClientRequest实现,ClientRequest的代码非常多,我们只分析核心的流程。我们看初始化一个请求的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54 | function ClientRequest(input, options, cb) {
// 继承OutgoingMessage
OutgoingMessage.call(this);
// 是否使用agent
let agent = options.agent;
// 忽略agent的处理,具体参考_http_agent.js,主要用于复用TCP连接
this.agent = agent;
// 建立连接的超时时间
if (options.timeout !== undefined)
this.timeout = getTimerDuration(options.timeout, 'timeout');
// HTTP头个数的阈值
const maxHeaderSize = options.maxHeaderSize;
this.maxHeaderSize = maxHeaderSize;
// 监听响应事件
if (cb) {
this.once('response', cb);
}
// 忽略设置http协议的请求行或请求头的逻辑
// 建立TCP连接后的回调
const oncreate = (err, socket) => {
if (called)
return;
called = true;
if (err) {
process.nextTick(() => this.emit('error', err));
return;
}
// 建立连接成功,执行回调
this.onSocket(socket);
// 连接成功后发送数据
this._deferToConnect(null, null, () => this._flush());
};
// 使用agent时,socket由agent提供,否则自己创建socket
if (this.agent) {
this.agent.addRequest(this, options);
} else {
// 不使用agent则每次创建一个socket,默认使用net模块的接口
if (typeof options.createConnection === 'function') {
const newSocket = options.createConnection(options,
oncreate);
if (newSocket && !called) {
called = true;
this.onSocket(newSocket);
} else {
return;
}
} else {
this.onSocket(net.createConnection(options));
}
}
// 连接成功后发送待缓存的数据
this._deferToConnect(null, null, () => this._flush());
}
|
获取一个ClientRequest实例后,不管是通过agent还是自己创建一个TCP连接,在连接成功后都会执行onSocket。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | // socket可用时的回调
ClientRequest.prototype.onSocket = function onSocket(socket) {
process.nextTick(onSocketNT, this, socket);
};
function onSocketNT(req, socket) {
// 申请socket过程中,请求已经终止
if (req.aborted) {
// 不使用agent,直接销毁socekt
if (!req.agent) {
socket.destroy();
} else {
// 使用agent触发free事件,由agent处理socekt
req.emit('close');
socket.emit('free');
}
} else {
// 处理socket
tickOnSocket(req, socket);
}
}
|
我们继续看tickOnSocket
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41 | // 初始化HTTP解析器和注册data事件等,等待响应
function tickOnSocket(req, socket) {
// 分配一个HTTP解析器
const parser = parsers.alloc();
req.socket = socket;
// 初始化,处理响应报文
parser.initialize(HTTPParser.RESPONSE,
new HTTPClientAsyncResource('HTTPINCOMINGMESSAGE', req), req.maxHeaderSize || 0,
req.insecureHTTPParser === undefined ?
isLenient() : req.insecureHTTPParser);
parser.socket = socket;
parser.outgoing = req;
req.parser = parser;
socket.parser = parser;
// socket正处理的请求
socket._httpMessage = req;
// Propagate headers limit from request object to parser
if (typeof req.maxHeadersCount === 'number') {
parser.maxHeaderPairs = req.maxHeadersCount << 1;
}
// 解析完HTTP头部的回调
parser.onIncoming = parserOnIncomingClient;
socket.removeListener('error', freeSocketErrorListener);
socket.on('error', socketErrorListener);
socket.on('data', socketOnData);
socket.on('end', socketOnEnd);
socket.on('close', socketCloseListener);
socket.on('drain', ondrain);
if (
req.timeout !== undefined ||
(req.agent && req.agent.options &&
req.agent.options.timeout)
) {
// 处理超时时间
listenSocketTimeout(req);
}
req.emit('socket', socket);
}
|
拿到一个socket后,就开始监听socket上http报文的到来。并且申请一个HTTP解析器准备解析http报文,我们主要分析超时时间的处理和data事件的处理逻辑。
1 超时时间的处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | function listenSocketTimeout(req) {
// 设置过了则返回
if (req.timeoutCb) {
return;
}
// 超时回调
req.timeoutCb = emitRequestTimeout;
// Delegate socket timeout event.
// 设置socket的超时时间,即socket上一定时间后没有响应则触发超时
if (req.socket) {
req.socket.once('timeout', emitRequestTimeout);
} else {
req.on('socket', (socket) => {
socket.once('timeout', emitRequestTimeout);
});
}
}
function emitRequestTimeout() {
const req = this._httpMessage;
if (req) {
req.emit('timeout');
}
}
|
2 处理响应数据
| function socketOnData(d) {
const socket = this;
const req = this._httpMessage;
const parser = this.parser;
// 交给HTTP解析器处理
const ret = parser.execute(d);
// ...
}
|
当Node.js收到响应报文时,会把数据交给HTTP解析器处理。http解析在解析的过程中会不断触发钩子函数。我们看一下JS层各个钩子函数的逻辑。
1 解析头部过程中执行的回调
| function parserOnHeaders(headers, url) {
// 保存头和url
if (this.maxHeaderPairs <= 0 ||
this._headers.length < this.maxHeaderPairs) {
this._headers = this._headers.concat(headers);
}
this._url += url;
}
|
2 解析完头部的回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55 | function parserOnHeadersComplete(versionMajor,
versionMinor,
headers,
method,
url,
statusCode,
statusMessage,
upgrade,
shouldKeepAlive) {
const parser = this;
const { socket } = parser;
// 剩下的HTTP头
if (headers === undefined) {
headers = parser._headers;
parser._headers = [];
}
if (url === undefined) {
url = parser._url;
parser._url = '';
}
// Parser is also used by http client
// IncomingMessage
const ParserIncomingMessage=(socket &&
socket.server &&
socket.server[kIncomingMessage]
) ||
IncomingMessage;
// 新建一个IncomingMessage对象
const incoming = parser.incoming = new ParserIncomingMessage(socket);
incoming.httpVersionMajor = versionMajor;
incoming.httpVersionMinor = versionMinor;
incoming.httpVersion = `${versionMajor}.${versionMinor}`;
incoming.url = url;
incoming.upgrade = upgrade;
let n = headers.length;
// If parser.maxHeaderPairs <= 0 assume that there's no limit.
if (parser.maxHeaderPairs > 0)
n = MathMin(n, parser.maxHeaderPairs);
// 更新到保存HTTP头的对象
incoming._addHeaderLines(headers, n);
// 请求方法或响应行信息
if (typeof method === 'number') {
// server only
incoming.method = methods[method];
} else {
// client only
incoming.statusCode = statusCode;
incoming.statusMessage = statusMessage;
}
// 执行回调
return parser.onIncoming(incoming, shouldKeepAlive);
}
|
我们看到解析完头部后会执行另一个回调onIncoming,并传入IncomingMessage实例,这就是我们平时使用的res。在前面分析过,onIncoming设置的值是parserOnIncomingClient。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | function parserOnIncomingClient(res, shouldKeepAlive) {
const socket = this.socket;
// 请求对象
const req = socket._httpMessage;
// 服务器发送了多个响应
if (req.res) {
socket.destroy();
return 0;
}
req.res = res;
if (statusIsInformational(res.statusCode)) {
req.res = null;
// 请求时设置了expect头,则响应码为100,可以继续发送数据
if (res.statusCode === 100) {
req.emit('continue');
}
return 1;
}
req.res = res;
res.req = req;
// 等待响应结束,响应结束后会清除定时器
res.on('end', responseOnEnd);
// 请求终止了或触发response事件,返回false说明没有监听response事件,则丢弃数据
if (req.aborted || !req.emit('response', res))
res._dump();
}
|
从源码中我们看出在解析完HTTP响应头时,就执行了http.request设置的回调函数。例如下面代码中的回调。
| http. request('domain', { agent }, (res) => {
// 解析body
res.on('data', (data) => {
//
});
// 解析body结束,响应结束
res.on('end', (data) => {
//
});
});
// ...
|
在回调里我们可以把res作为一个流使用,在解析完HTTP头后,HTTP解析器会继续解析HTTP body。我们看一下HTTP解析器在解析body过程中执行的回调。
| function parserOnBody(b, start, len) {
const stream = this.incoming;
if (len > 0 && !stream._dumped) {
const slice = b.slice(start, start + len);
// 把数据push到流中,流会触发data事件
const ret = stream.push(slice);
// 数据过载,暂停接收
if (!ret)
readStop(this.socket);
}
}
|
最后我们再看一下解析完body时HTTP解析器执行的回调。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | function parserOnMessageComplete() {
const parser = this;
const stream = parser.incoming;
if (stream !== null) {
// body解析完了
stream.complete = true;
// 在body后可能有trailer头,保存下来
const headers = parser._headers;
if (headers.length) {
stream._addHeaderLines(headers, headers.length);
parser._headers = [];
parser._url = '';
}
// 流结束
stream.push(null);
}
// 读取下一个响应,如果有的话
readStart(parser.socket);
}
|
我们看到在解析body过程中会不断往流中push数据,从而不断触发res的data事件,最后解析body结束后,通过push(null)通知流结束,从而触发res.end事件。我们沿着onSocket函数分析完处理响应后我们再来分析请求的过程。执行完http.request后我们会得到一个标记请求的实例。然后执行它的write方法发送数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38 | OutgoingMessage.prototype.write = function write(chunk, encoding, callback) {
const ret = write_(this, chunk, encoding, callback, false);
// 返回false说明需要等待drain事件
if (!ret)
this[kNeedDrain] = true;
return ret;
};
function write_(msg, chunk, encoding, callback, fromEnd) {
// 还没有设置this._header字段,则把请求行和HTTP头拼接到this._header字段
if (!msg._header) {
msg._implicitHeader();
}
let ret;
// chunk模式则需要额外加一下字段,否则直接发送
if (msg.chunkedEncoding && chunk.length !== 0) {
let len;
if (typeof chunk === 'string')
len = Buffer.byteLength(chunk, encoding);
else
len = chunk.length;
/*
chunk模式时,http报文的格式如下
chunk长度 回车换行
数据 回车换行
*/
msg._send(len.toString(16), 'latin1', null);
msg._send(crlf_buf, null, null);
msg._send(chunk, encoding, null);
ret = msg._send(crlf_buf, null, callback);
} else {
ret = msg._send(chunk, encoding, callback);
}
return ret;
}
|
我们接着看_send函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | OutgoingMessage.prototype._send = function _send(data, encoding, callback) {
// 头部还没有发送
if (!this._headerSent) {
// 是字符串则追加到头部,this._header保存了HTTP请求行和HTTP头
if (typeof data === 'string' &&
(encoding === 'utf8' ||
encoding === 'latin1' ||
!encoding)) {
data = this._header + data;
} else {
// 否则缓存起来
const header = this._header;
// HTTP头需要放到最前面
if (this.outputData.length === 0) {
this.outputData = [{
data: header,
encoding: 'latin1',
callback: null
}];
} else {
this.outputData.unshift({
data: header,
encoding: 'latin1',
callback: null
});
}
// 更新缓存大小
this.outputSize += header.length;
this._onPendingData(header.length);
}
// 已经在排队等待发送了,不能修改
this._headerSent = true;
}
return this._writeRaw(data, encoding, callback);
};
|
我们继续看_writeRaw
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46 | OutgoingMessage.prototype._writeRaw = function _writeRaw(data, encoding, callback) {
// 可写的时候直接发送
if (conn && conn._httpMessage === this && conn.writable) {
// There might be pending data in the this.output buffer.
// 如果有缓存的数据则先发送缓存的数据
if (this.outputData.length) {
this._flushOutput(conn);
}
// 接着发送当前需要发送的
return conn.write(data, encoding, callback);
}
// 否先缓存
this.outputData.push({ data, encoding, callback });
this.outputSize += data.length;
this._onPendingData(data.length);
return this.outputSize < HIGH_WATER_MARK;
}
OutgoingMessage.prototype._flushOutput = function _flushOutput(socket) {
// 之前设置了加塞,则操作socket先积攒数据
while (this[kCorked]) {
this[kCorked]--;
socket.cork();
}
const outputLength = this.outputData.length;
if (outputLength <= 0)
return undefined;
const outputData = this.outputData;
socket.cork();
// 把缓存的数据写到socket
let ret;
for (let i = 0; i < outputLength; i++) {
const { data, encoding, callback } = outputData[i];
ret = socket.write(data, encoding, callback);
}
socket.uncork();
this.outputData = [];
this._onPendingData(-this.outputSize);
this.outputSize = 0;
return ret;
};
|
写完数据后,我们还需要执行end函数标记HTTP请求的结束。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37 | OutgoingMessage.prototype.end = function end(chunk, encoding, callback) {
// 还没结束
// 加塞
if (this.socket) {
this.socket.cork();
}
// 流结束后回调
if (typeof callback === 'function')
this.once('finish', callback);
// 数据写入底层后的回调
const finish = onFinish.bind(undefined, this);
// chunk模式后面需要发送一个0\r\n结束标记,否则不需要结束标记
if (this._hasBody && this.chunkedEncoding) {
this._send('0\r\n' +
this._trailer + '\r\n', 'latin1', finish);
} else {
this._send('', 'latin1', finish);
}
// uncork解除塞子,发送数据
if (this.socket) {
// Fully uncork connection on end().
this.socket._writableState.corked = 1;
this.socket.uncork();
}
this[kCorked] = 0;
// 标记执行了end
this.finished = true;
// 数据发完了
if (this.outputData.length === 0 &&
this.socket &&
this.socket._httpMessage === this) {
this._finish();
}
return this;
};
|
18.3 HTTP服务器
本节我们来分析使用Node.js作为服务器的例子。
| const http = require('http');
http.createServer((req, res) => {
res.write('hello');
res.end();
})
.listen(3000);
|
接着我们沿着createServer分析Node.js作为服务器的原理。
| function createServer(opts, requestListener) {
return new Server(opts, requestListener);
}
|
我们看Server的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 | function Server(options, requestListener) {
// 可以自定义表示请求的对象和响应的对象
this[kIncomingMessage] = options.IncomingMessage || IncomingMessage;
this[kServerResponse] = options.ServerResponse || ServerResponse;
// HTTP头个数的阈值
const maxHeaderSize = options.maxHeaderSize;
this.maxHeaderSize = maxHeaderSize;
// 允许半关闭
net.Server.call(this, { allowHalfOpen: true });
// 有请求时的回调
if (requestListener) {
this.on('request', requestListener);
}
// 服务器socket读端关闭时是否允许继续处理队列里的响应(tcp上有多个请求,管道化)
this.httpAllowHalfOpen = false;
// 有连接时的回调,由net模块触发
this.on('connection', connectionListener);
// 服务器下所有请求和响应的超时时间
this.timeout = 0;
// 同一个TCP连接上,两个请求之前最多间隔的时间
this.keepAliveTimeout = 5000;
this.maxHeadersCount = null;
// 解析头部的超时时间,防止ddos
this.headersTimeout = 60 * 1000; // 60 seconds
}
|
接着调用listen函数,因为HTTP Server继承于net.Server,net.Server的listen函数前面我们已经分析过,就不再分析。当有请求到来时,会触发connection事件。从而执行connectionListener。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92 | function connectionListener(socket) {
defaultTriggerAsyncIdScope(
getOrSetAsyncId(socket), connectionListenerInternal, this, socket
);
}
// socket表示新连接
function connectionListenerInternal(server, socket) {
// socket所属server
socket.server = server;
// 设置连接的超时时间,超时处理函数为socketOnTimeout
if (server.timeout && typeof socket.setTimeout === 'function') socket.setTimeout(server.timeout);
socket.on('timeout', socketOnTimeout);
// 分配一个HTTP解析器
const parser = parsers.alloc();
// 解析请求报文
parser.initialize(
HTTPParser.REQUEST,
new HTTPServerAsyncResource('HTTPINCOMINGMESSAGE', socket),
server.maxHeaderSize || 0,
server.insecureHTTPParser === undefined ?
isLenient() : server.insecureHTTPParser,
);
parser.socket = socket;
// 记录开始解析头部的开始时间
parser.parsingHeadersStart = nowDate();
socket.parser = parser;
if (typeof server.maxHeadersCount === 'number') {
parser.maxHeaderPairs = server.maxHeadersCount << 1;
}
const state = {
onData: null,
onEnd: null,
onClose: null,
onDrain: null,
// 同一TCP连接上,请求和响应的的队列,线头阻塞的原理
outgoing: [],
incoming: [],
// 待发送的字节数,如果超过阈值,则先暂停接收请求的数据
outgoingData: 0,
/*
是否重新设置了timeout,用于响应一个请求时,
标记是否重新设置超时时间的标记
*/
keepAliveTimeoutSet: false
};
// 监听tcp上的数据,开始解析http报文
state.onData = socketOnData.bind(undefined,
server,
socket,
parser,
state);
state.onEnd = socketOnEnd.bind(undefined,
server,
socket,
parser,
state);
state.onClose = socketOnClose.bind(undefined, socket, state);
state.onDrain = socketOnDrain.bind(undefined, socket, state);
socket.on('data', state.onData);
socket.on('error', socketOnError);
socket.on('end', state.onEnd);
socket.on('close', state.onClose);
socket.on('drain', state.onDrain);
// 解析HTTP头部完成后执行的回调
parser.onIncoming = parserOnIncoming.bind(undefined,
server,
socket,
state);
socket.on('resume', onSocketResume);
socket.on('pause', onSocketPause);
/*
如果handle是继承StreamBase的流则执行consume消费http
请求报文,而不是上面的onData,tcp模块的isStreamBase为true
*/
if (socket._handle && socket._handle.isStreamBase &&
!socket._handle._consumed) {
parser._consumed = true;
socket._handle._consumed = true;
parser.consume(socket._handle);
}
parser[kOnExecute] =
onParserExecute.bind(undefined,
server,
socket,
parser,
state);
socket._paused = false;
}
|
执行完connectionListener后就开始等待tcp上数据的到来,即HTTP请求报文。上面代码中Node.js监听了socket的data事件,同时注册了钩子kOnExecute。data事件我们都知道是流上有数据到来时触发的事件。我们看一下socketOnData做了什么事情。
| function socketOnData(server, socket, parser, state, d) {
// 交给HTTP解析器处理,返回已经解析的字节数
const ret = parser.execute(d);
onParserExecuteCommon(server, socket, parser, state, ret, d);
}
|
socketOnData的处理逻辑是当socket上有数据,然后交给HTTP解析器处理。这看起来没什么问题,那么kOnExecute是做什么的呢?kOnExecute钩子函数的值是onParserExecute,这个看起来也是解析tcp上的数据的,看起来和onSocketData是一样的作用,难道tcp上的数据有两个消费者?我们看一下kOnExecute什么时候被回调的。
| void OnStreamRead(ssize_t nread, const uv_buf_t& buf) override {
Local<Value> ret = Execute(buf.base, nread);
Local<Value> cb =
object()->Get(env()->context(), kOnExecute).ToLocalChecked();
MakeCallback(cb.As<Function>(), 1, &ret);
}
|
OnStreamRead是node_http_parser.cc实现的函数,所以kOnExecute在node_http_parser.cc中的OnStreamRead中被回调,那么OnStreamRead又是什么时候被回调的呢?在C++层章节我们分析过,OnStreamRead是Node.js中C++层流操作的通用函数,当流有数据的时候就会执行该回调。而且OnStreamRead中也会把数据交给HTTP解析器解析。这看起来真的有两个消费者?这就很奇怪,为什么一份数据会交给HTTP解析器处理两次?
| if (socket._handle && socket._handle.isStreamBase && !socket._handle._consumed) {
parser._consumed = true;
socket._handle._consumed = true;
parser.consume(socket._handle);
}
|
因为TCP流是继承StreamBase类的,所以if成立。我们看一下consume的实现。
| static void Consume(const FunctionCallbackInfo<Value>& args) {
Parser* parser;
ASSIGN_OR_RETURN_UNWRAP(&parser, args.Holder());
CHECK(args[0]->IsObject());
StreamBase* stream = StreamBase::FromObjject(args[0].As<Object>());
CHECK_NOT_NULL(stream);
stream->PushStreamListener(parser);
}
|
HTTP解析器把自己注册为TCP stream的一个listener。这会使得TCP流上的数据由node_http_parser.cc的OnStreamRead直接消费,而不是触发onData事件。在OnStreamRead中会源源不断地把数据交给HTTP解析器处理,在解析的过程中,会不断触发对应的钩子函数,直到解析完HTTP头部后执行parserOnIncoming。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83 | function parserOnIncoming(server, socket, state, req, keepAlive) {
// 需要重置定时器
resetSocketTimeout(server, socket, state);
// 设置了keepAlive则响应后需要重置一些状态
if (server.keepAliveTimeout > 0) {
req.on('end', resetHeadersTimeoutOnReqEnd);
}
// 标记头部解析完毕
socket.parser.parsingHeadersStart = 0;
// 请求入队(待处理的请求队列)
state.incoming.push(req);
if (!socket._paused) {
const ws = socket._writableState;
// 待发送的数据过多,先暂停接收请求数据
if (ws.needDrain ||
state.outgoingData >= socket.writableHighWaterMark) {
socket._paused = true;
socket.pause();
}
}
// 新建一个表示响应的对象
const res = new server[kServerResponse](req);
// 设置数据写入待发送队列时触发的回调,见OutgoingMessage
res._onPendingData = updateOutgoingData.bind(undefined,
socket,
state);
// 根据请求的HTTP头设置是否支持keepalive(管道化)
res.shouldKeepAlive = keepAlive;
/*
socket当前已经在处理其它请求的响应,则先排队,
否则挂载响应对象到socket,作为当前处理的响应
*/
if (socket._httpMessage) {
state.outgoing.push(res);
} else {
res.assignSocket(socket);
}
// 响应处理完毕后,需要做一些处理
res.on('finish',
resOnFinish.bind(undefined,
req,
res,
socket,
state,
server));
// 有expect请求头,并且是http1.1
if (req.headers.expect !== undefined &&
(req.httpVersionMajor === 1 &&
req.httpVersionMinor === 1)
) {
// Expect头的值是否是100-continue
if (continueExpression.test(req.headers.expect)) {
res._expect_continue = true;
/*
监听了checkContinue事件则触发,
否则直接返回允许继续请求并触发request事件
*/
if (server.listenerCount('checkContinue') > 0) {
server.emit('checkContinue', req, res);
} else {
res.writeContinue();
server.emit('request', req, res);
}
} else if (server.listenerCount('checkExpectation') > 0) {
/*
值异常,监听了checkExpectation事件,
则触发,否则返回417拒绝请求
*/
server.emit('checkExpectation', req, res);
} else {
res.writeHead(417);
res.end();
}
} else {
// 触发request事件说明有请求到来
server.emit('request', req, res);
}
return 0; // No special treatment.
}
|
我们看到这里会触发request事件通知用户有新请求到来,用户就可以处理请求了。我们看到Node.js解析头部的时候就会执行上层回调,通知有新请求到来,并传入request和response作为参数,分别对应的是表示请求和响应的对象。另外Node.js本身是不会解析body部分的,我们可以通过以下方式获取body的数据。
| const server = http.createServer((request, response) => {
request.on('data', (chunk) => {
// 处理body
});
request.on('end', () => {
// body结束
});
})
|
18.3.1 HTTP管道化的原理和实现
HTTP1.0的时候,不支持管道化,客户端发送一个请求的时候,首先建立TCP连接,然后服务器返回一个响应,最后断开TCP连接,这种是最简单的实现方式,但是每次发送请求都需要走三次握手显然会带来一定的时间损耗,所以HTTP1.1的时候,支持了管道化。管道化的意思就是可以在一个TCP连接上发送多个请求,这样服务器就可以同时处理多个请求,但是由于HTTP1.1的限制,多个请求的响应需要按序返回。因为在HTTP1.1中,没有标记请求和响应的对应关系。所以HTTP客户端会假设第一个返回的响应是对应第一个请求的。如果乱序返回,就会导致问题,如图18-2所示。
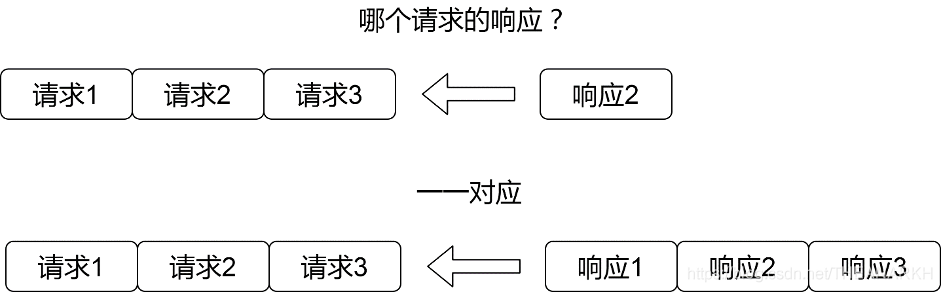
图18-2
而在HTTP 2.0中,每个请求会分配一个id,响应中也会返回对应的id,这样就算乱序返回,HTTP客户端也可以知道响应所对应的请求。在HTTP 1.1这种情况下,HTTP服务器的实现就会变得复杂,服务器可以以串行的方式处理请求,当前面请求的响应返回到客户端后,再继续处理下一个请求,这种实现方式是相对简单的,但是很明显,这种方式相对来说还是比较低效的,另一种实现方式是并行处理请求,串行返回,这样可以让请求得到尽快的处理,比如两个请求都访问数据库,那并行处理两个请求就会比串行快得多,但是这种实现方式相对比较复杂,Node.js就是属于这种方式,下面我们来看一下Node.js中是如何实现的。前面分析过,Node.js在解析完HTTP头部的时候会执行parserOnIncoming。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | function parserOnIncoming(server, socket, state, req, keepAlive) {
// 标记头部解析完毕
socket.parser.parsingHeadersStart = 0;
// 请求入队
state.incoming.push(req);
// 新建一个表示响应的对象,一般是ServerResponse
const res = new server[kServerResponse](req);
/*
socket当前已经在处理其它请求的响应,则先排队,
否则挂载响应对象到socket,作为当前处理的响应
*/
if (socket._httpMessage) {
state.outgoing.push(res);
} else {
res.assignSocket(socket); // socket._httpMessage = res;
}
// 响应处理完毕后,需要做一些处理
res.on('finish', resOnFinish.bind(undefined,
req,
res,
socket,
state,
server));
// 触发request事件说明有请求到来
server.emit('request', req, res);
return 0;
}
|
当Node.js解析HTTP请求头完成后,就会创建一个ServerResponse对象表示响应。然后判断当前是否有正在处理的响应,如果有则排队等待处理,否则把新建的ServerResponse对象作为当前需要处理的响应。最后触发request事件通知用户层。用户就可以进行请求的处理了。我们看到Node.js维护了两个队列,分别是请求和响应队列,如图18-3所示。

图18-3
当前处理的请求在请求队列的队首,该请求对应的响应会挂载到socket的_httpMessage属性上。但是我们看到Node.js会触发request事件通知用户有新请求到来,所有在管道化的情况下,Node.js会并行处理多个请求(如果是cpu密集型的请求则实际上还是会变成串行,这和Node.js的单线程相关)。那Node.js是如何控制响应的顺序的呢?我们知道每次触发request事件的时候,我们都会执行一个函数。比如下面的代码。
| http.createServer((req, res) => {
// 一些网络IO
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('okay');
});
|
我们看到每个请求的处理是独立的。假设每个请求都去操作数据库,如果请求2比请求1先完成数据库的操作,从而请求2先执行res.write和res.end。那岂不是请求2先返回?我们看一下ServerResponse和OutgoingMessage的实现,揭开迷雾。ServerResponse是OutgoingMessage的子类。write函数是在OutgoingMessage中实现的,write的调用链路很长,我们不层层分析,直接看最后的节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | function _writeRaw(data, encoding, callback) {
const conn = this.socket;
// socket对应的响应是自己并且可写
if (conn && conn._httpMessage === this && conn.writable) {
// 如果有缓存的数据则先发送缓存的数据
if (this.outputData.length) {
this._flushOutput(conn);
}
// 接着发送当前需要发送的
return conn.write(data, encoding, callback);
}
// socket当前处理的响应对象不是自己,则先缓存数据。
this.outputData.push({ data, encoding, callback });
this.outputSize += data.length;
this._onPendingData(data.length);
return this.outputSize < HIGH_WATER_MARK;
}
|
我们看到我们调用res.write的时候,Node.js会首先判断,res是不是属于当前处理中响应,如果是才会真正发送数据,否则会先把数据缓存起来。分析到这里,相信大家已经差不多明白Node.js是如何控制响应按序返回的。最后我们看一下这些缓存的数据什么时候会被发送出去。前面代码已经贴过,当一个响应结束的时候,Node.js会做一些处理。
| res.on('finish', resOnFinish.bind(undefined,
req,
res,
socket,
state,
server));
|
我们看看resOnFinish
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | function resOnFinish(req, res, socket, state, server) {
// 删除响应对应的请求
state.incoming.shift();
clearIncoming(req);
// 解除socket上挂载的响应对象
res.detachSocket(socket);
req.emit('close');
process.nextTick(emitCloseNT, res);
// 是不是最后一个响应
if (res._last) {
// 是则销毁socket
if (typeof socket.destroySoon === 'function') {
socket.destroySoon();
} else {
socket.end();
}
} else if (state.outgoing.length === 0) {
/*
没有待处理的响应了,则重新设置超时时间,
等待请求的到来,一定时间内没有请求则触发timeout事件
*/
if (server.keepAliveTimeout &&
typeof socket.setTimeout === 'function') {
socket.setTimeout(server.keepAliveTimeout);
state.keepAliveTimeoutSet = true;
}
} else {
// 获取下一个要处理的响应
const m = state.outgoing.shift();
// 挂载到socket作为当前处理的响应
if (m) {
m.assignSocket(socket);
}
}
}
|
我们看到,Node.js处理完一个响应后,会做一些判断。分别有三种情况,我们分开分析。
1 是否是最后一个响应
什么情况下,会被认为是最后一个响应的?因为响应和请求是一一对应的,最后一个响应就意味着最后一个请求了,那么什么时候被认为是最后一个请求呢?当非管道化的情况下,一个请求一个响应,然后关闭TCP连接,所以非管道化的情况下,tcp上的第一个也是唯一一个请求就是最后一个请求。在管道化的情况下,理论上就没有所谓的最后一个响应。但是实现上会做一些限制。在管道化的情况下,每一个响应可以通过设置HTTP响应头connection来定义是否发送该响应后就断开连接,我们看一下Node.js的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | // 是否显示删除过connection头,是则响应后断开连接,并标记当前响应是最后一个
if (this._removedConnection) {
this._last = true;
this.shouldKeepAlive = false;
} else if (!state.connection) {
/*
没有显示设置了connection头,则取默认行为
1 Node.js的shouldKeepAlive默认为true,也可以根据请求报文里
的connection头定义
2 设置content-length或使用chunk模式才能区分响应报文编边界,
才能支持keepalive
3 使用了代理,代理是复用TCP连接的,支持keepalive
*/
const shouldSendKeepAlive = this.shouldKeepAlive &&
(state.contLen ||
this.useChunkedEncodingByDefault ||
this.agent);
if (shouldSendKeepAlive) {
header += 'Connection: keep-alive\r\n';
} else {
this._last = true;
header += 'Connection: close\r\n';
}
}
|
另外当读端关闭的时候,也被认为是最后一个请求,毕竟不会再发送请求了。我们看一下读端关闭的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | function socketOnEnd(server, socket, parser, state) {
const ret = parser.finish();
if (ret instanceof Error) {
socketOnError.call(socket, ret);
return;
}
// 不允许半开关则终止请求的处理,不响应,关闭写端
if (!server.httpAllowHalfOpen) {
abortIncoming(state.incoming);
if (socket.writable) socket.end();
} else if (state.outgoing.length) {
/*
允许半开关,并且还有响应需要处理,
标记响应队列最后一个节点为最后的响应,
处理完就关闭socket写端
*/
state.outgoing[state.outgoing.length - 1]._last = true;
} else if (socket._httpMessage) {
/*
没有等待处理的响应了,但是还有正在处理的响应,
则标记为最后一个响应
*/
socket._httpMessage._last = true;
} else if (socket.writable) {
// 否则关闭socket写端
socket.end();
}
}
|
以上就是Node.js中判断是否是最后一个响应的情况,如果一个响应被认为是最后一个响应,那么发送响应后就会关闭连接。
2 响应队列为空
我们继续看一下如果不是最后一个响应的时候,Node.js又是怎么处理的。如果当前的待处理响应队列为空,说明当前处理的响应是目前最后一个需要处理的,但是不是TCP连接上最后一个响应,这时候,Node.js会设置超时时间,如果超时还没有新的请求,则Node.js会关闭连接。
3 响应队列非空
如果当前待处理队列非空,处理完当前请求后会继续处理下一个响应。并从队列中删除该响应。我们看一下Node.js是如何处理下一个响应的。
| // 把响应对象挂载到socket,标记socket当前正在处理的响应
ServerResponse.prototype.assignSocket = function assignSocket(socket) {
// 挂载到socket上,标记是当前处理的响应
socket._httpMessage = this;
socket.on('close', onServerResponseClose);
this.socket = socket;
this.emit('socket', socket);
this._flush();
};
|
我们看到Node.js是通过_httpMessage标记当前处理的响应的,配合响应队列来实现响应的按序返回。标记完后执行_flush发送响应的数据(如果这时候请求已经被处理完成)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | OutgoingMessage.prototype._flush = function _flush() {
const socket = this.socket;
if (socket && socket.writable) {
const ret = this._flushOutput(socket);
};
OutgoingMessage.prototype._flushOutput = function _flushOutput(socket) {
// 之前设置了加塞,则操作socket先积攒数据
while (this[kCorked]) {
this[kCorked]--;
socket.cork();
}
const outputLength = this.outputData.length;
// 没有数据需要发送
if (outputLength <= 0)
return undefined;
const outputData = this.outputData;
// 加塞,让数据一起发送出去
socket.cork();
// 把缓存的数据写到socket
let ret;
for (let i = 0; i < outputLength; i++) {
const { data, encoding, callback } = outputData[i];
ret = socket.write(data, encoding, callback);
}
socket.uncork();
this.outputData = [];
this._onPendingData(-this.outputSize);
this.outputSize = 0;
return ret;
}
|
以上就是Node.js中对于管道化的实现。
18.3.2 HTTP Connect方法的原理和实现
分析HTTP Connect实现之前我们首先看一下为什么需要HTTP Connect方法或者说它出现的背景。Connect方法主要用于代理服务器的请求转发。我们看一下传统HTTP服务器的工作原理,如图18-4所示。
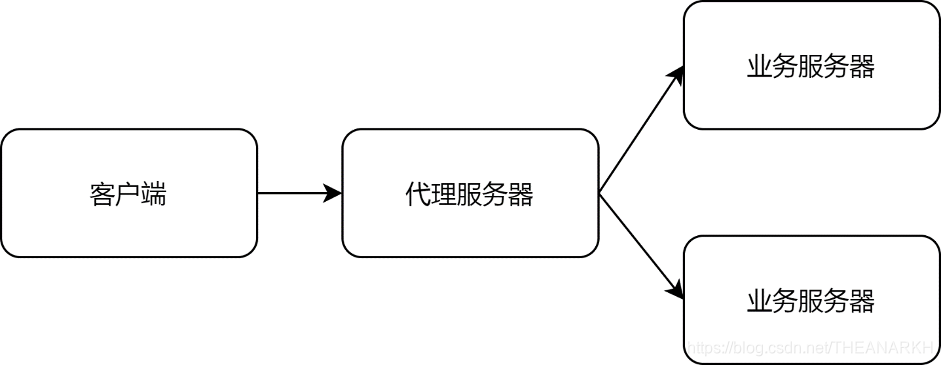
图18-4
1 客户端和代理服务器建立TCP连接
2 客户端发送HTTP请求给代理服务器
3 代理服务器解析HTTP协议,根据配置拿到业务服务器的地址
4 代理服务器和业务服务器建立TCP连接,通过HTTP协议或者其它协议转发请求
5 业务服务器返回数据,代理服务器回复HTTP报文给客户端。
接着我们看一下HTTPS服务器的原理。
1 客户端和服务器建立TCP连接
2 服务器通过TLS报文返回证书信息,并和客户端完成后续的TLS通信。
3 完成TLS通信后,后续发送的HTTP报文会经过TLS层加密解密后再传输。
那么如果我们想实现一个HTTPS的代理服务器怎么做呢?因为客户端只管和直接相连的服务器进行HTTPS的通信,如果我们的业务服务器前面还有代理服务器,那么代理服务器就必须要有证书才能和客户端完成TLS握手,从而进行HTTPS通信。代理服务器和业务服务器使用HTTP或者HTTPS还是其它协议都可以。这样就意味着我们所有的服务的证书都需要放到代理服务器上,这种场景的限制是,代理服务器和业务服务器都由我们自己管理或者公司统一管理。如果我们想加一个代理对业务服务器不感知那怎么办呢(比如写一个代理服务器用于开发调试)?有一种方式就是为我们的代理服务器申请一个证书,这样客户端和代理服务器就可以完成正常的HTTPS通信了。从而也就可以完成代理的功能。另外一种方式就是HTTP Connect方法。HTTP Connect方法的作用是指示服务器帮忙建立一条TCP连接到真正的业务服务器,并且透传后续的数据,这样不申请证书也可以完成代理的功能,如图18-5所示。

图18-5
这时候代理服务器只负责透传两端的数据,不像传统的方式一样解析请求然后再转发。这样客户端和业务服务器就可以自己完成TLS握手和HTTPS通信。代理服务器就像不存在一样。了解了Connect的原理后看一下来自Node.js官方的一个例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52 | const http = require('http');
const net = require('net');
const { URL } = require('url');
// 创建一个HTTP服务器作为代理服务器
const proxy = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('okay');
});
// 监听connect事件,有http connect请求时触发
proxy.on('connect', (req, clientSocket, head) => {
// 获取真正要连接的服务器地址并发起连接
const { port, hostname } = new URL(`http://${req.url}`);
const serverSocket = net.connect(port || 80, hostname, () => {
// 连接成功告诉客户端
clientSocket.write('HTTP/1.1 200 Connection Established\r\n' +
'Proxy-agent: Node.js-Proxy\r\n' +
'\r\n');
// 透传客户端和服务器的数据
serverSocket.write(head);
serverSocket.pipe(clientSocket);
clientSocket.pipe(serverSocket);
});
});
proxy.listen(1337, '127.0.0.1', () => {
const options = {
port: 1337,
// 连接的代理服务器地址
host: '127.0.0.1',
method: 'CONNECT',
// 我们需要真正想访问的服务器地址
path: 'www.baidu.com',
};
// 发起http connect请求
const req = http.request(options);
req.end();
// connect请求成功后触发
req.on('connect', (res, socket, head) => {
// 发送真正的请求
socket.write('GET / HTTP/1.1\r\n' +
'Host: www.baidu.com\r\n' +
'Connection: close\r\n' +
'\r\n');
socket.on('data', (chunk) => {
console.log(chunk.toString());
});
socket.on('end', () => {
proxy.close();
});
});
});
|
官网的这个例子很好地说明了Connect的原理,如图18-6所示。

图18-6
下面我们看一下Node.js中Connect的实现。我们从HTTP Connect请求开始。之前已经分析过,客户端和Node.js服务器建立TCP连接后,Node.js收到数据的时候会交给HTTP解析器处理,
| // 连接上有数据到来
function socketOnData(server, socket, parser, state, d) {
// 交给HTTP解析器处理,返回已经解析的字节数
const ret = parser.execute(d);
onParserExecuteCommon(server, socket, parser, state, ret, d);
}
|
HTTP解析数据的过程中会不断回调Node.js的回调,然后执行onParserExecuteCommon。我们这里只关注当Node.js解析完所有HTTP请求头后执行parserOnHeadersComplete。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | function parserOnHeadersComplete(versionMajor, versionMinor, headers, method,
url, statusCode, statusMessage, upgrade,
shouldKeepAlive) {
const parser = this;
const { socket } = parser;
// IncomingMessage
const ParserIncomingMessage = (socket && socket.server &&
socket.server[kIncomingMessage]) ||
IncomingMessage;
// 新建一个IncomingMessage对象
const incoming = parser.incoming = new ParserIncomingMessage(socket);
incoming.httpVersionMajor = versionMajor;
incoming.httpVersionMinor = versionMinor;
incoming.httpVersion = `${versionMajor}.${versionMinor}`;
incoming.url = url;
// 是否是connect请求或者upgrade请求
incoming.upgrade = upgrade;
// 执行回调
return parser.onIncoming(incoming, shouldKeepAlive);
}
|
我们看到解析完HTTP头后,Node.js会创建一个表示请求的对象IncomingMessage,然后回调onIncoming。
| function parserOnIncoming(server, socket, state, req, keepAlive) {
// 请求是否是connect或者upgrade
if (req.upgrade) {
req.upgrade = req.method === 'CONNECT' ||
server.listenerCount('upgrade') > 0;
if (req.upgrade)
return 2;
}
// ...
}
|
Node.js解析完头部并且执行了响应的钩子函数后,会执行onParserExecuteCommon。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | function onParserExecuteCommon(server, socket, parser, state, ret, d) {
if (ret instanceof Error) {
prepareError(ret, parser, d);
ret.rawPacket = d || parser.getCurrentBuffer();
socketOnError.call(socket, ret);
} else if (parser.incoming && parser.incoming.upgrade) {
// 处理Upgrade或者CONNECT请求
const req = parser.incoming;
const eventName = req.method === 'CONNECT' ?
'connect' : 'upgrade';
// 监听了对应的事件则处理,否则关闭连接
if (eventName === 'upgrade' ||
server.listenerCount(eventName) > 0) {
// 还没有解析的数据
const bodyHead = d.slice(ret, d.length);
socket.readableFlowing = null;
server.emit(eventName, req, socket, bodyHead);
} else {
socket.destroy();
}
}
}
|
这时候Node.js会判断请求是不是Connect或者协议升级的upgrade请求,是的话继续判断是否有处理该事件的函数,没有则关闭连接,否则触发对应的事件进行处理。所以这时候Node.js会触发Connect方法。Connect事件的处理逻辑正如我们开始给出的例子中那样。我们首先和真正的服务器建立TCP连接,然后返回响应头给客户端,后续客户就可以和真正的服务器真正进行TLS握手和HTTPS通信了。这就是Node.js中Connect的原理和实现。
不过在代码中我们发现一个好玩的地方。那就是在触发connect事件的时候,Node.js给回调函数传入的参数。
| server.emit('connect', req, socket, bodyHead);
|
第一第二个参数没什么特别的,但是第三个参数就有意思了,bodyHead代表的是HTTP Connect请求中除了请求行和HTTP头之外的数据。因为Node.js解析完HTTP头后就不继续处理了。把剩下的数据交给了用户。我们来做一些好玩的事情。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | const http = require('http');
const net = require('net');
const { URL } = require('url');
const proxy = http.createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('okay');
});
proxy.on('connect', (req, clientSocket, head) => {
const { port, hostname } = new URL(`http://${req.url}`);
const serverSocket = net.connect(port || 80, hostname, () => {
clientSocket.write('HTTP/1.1 200 Connection Established\r\n' +
'Proxy-agent: Node.js-Proxy\r\n' +
'\r\n');
// 把connect请求剩下的数据转发给服务器
serverSocket.write(head);
serverSocket.pipe(clientSocket);
clientSocket.pipe(serverSocket);
});
});
proxy.listen(1337, '127.0.0.1', () => {
const net = require('net');
const body = 'GET http://www.baidu.com:80 HTTP/1.1\r\n\r\n';
const length = body.length;
const socket = net.connect({host: '127.0.0.1', port: 1337});
socket.write(`CONNECT www.baidu.com:80 HTTP/1.1\r\n\r\n${body}`);
socket.setEncoding('utf-8');
socket.on('data', (chunk) => {
console.log(chunk)
});
});
|
我们新建一个socket,然后自己构造HTTP Connect报文,并且在HTTP行后面加一个额外的字符串,这个字符串是两一个HTTP请求。当Node.js服务器收到Connect请求后,我们在connect事件的处理函数中,把Connect请求多余的那一部分数据传给真正的服务器。这样就节省了发送一个请求的时间。
18.3.3 超时管理
在解析HTTP协议或者支持长连接的时候,Node.js需要设置一些超时的机制,否则会造成攻击或者资源浪费。下面我们看一下HTTP服务器中涉及到超时的一些逻辑。 1 解析HTTP头部超时
当收到一个HTTP请求报文时,会从HTTP请求行,HTTP头,HTTP body的顺序进行解析,如果用户构造请求,只发送HTTP头的一部分。那么HTTP解析器就会一直在等待后续数据的到来。这会导致DDOS攻击,所以Node.js中设置了解析HTTP头的超时时间,阈值是60秒。如果60秒内没有解析完HTTP头部,则会触发timeout事件。如果用户不处理,则Node.js会自动关闭连接。我们看一下Node.js的实现。Node.js在初始化的时候会设置超时时间。
| this.headersTimeout = 60 * 1000; // 60 seconds
// Node.js在建立TCP连接成功后初始化解析HTTP头的开始时间。
function connectionListenerInternal(server, socket) {
parser.parsingHeadersStart = nowDate();
}
|
然后在每次收到数据的时候判断HTTP头部是否解析完成,如果没有解析完成并且超时了则会触发timeout事件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | function onParserExecute(server, socket, parser, state, ret) {
socket._unrefTimer();
const start = parser.parsingHeadersStart;
// start等于0,说明HTTP头已经解析完毕,否则说明正在解析头,然后再判断解析时间是否超时了
if (start !== 0 && nowDate() - start > server.headersTimeout) {
// 触发timeout,如果没有监听timeout,则默认会销毁socket,即关闭连接
const serverTimeout = server.emit('timeout', socket);
if (!serverTimeout)
socket.destroy();
return;
}
onParserExecuteCommon(server, socket, parser, state, ret, undefined);
}
|
如果在超时之前解析HTTP头完成,则把parsingHeadersStart置为0表示解析完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | function parserOnIncoming(server, socket, state, req, keepAlive) {
// 设置了keepAlive则响应后需要重置一些状态
if (server.keepAliveTimeout > 0) {
req.on('end', resetHeadersTimeoutOnReqEnd);
}
// 标记头部解析完毕
socket.parser.parsingHeadersStart = 0;
}
function resetHeadersTimeoutOnReqEnd() {
if (parser) {
parser.parsingHeadersStart = nowDate();
}
}
|
另外如果支持长连接,即一个TCP连接上可以发送多个请求。则在每个响应结束之后,需要重新初始化解析HTTP头的开始时间。当下一个请求数据到来时再次判断解析HTTP头部是否超时。这里是响应结束后就开始计算。而不是下一个请求到来时。 2 支持管道化的情况下,多个请求的时间间隔
Node.js支持在一个TCP连接上发送多个HTTP请求,所以需要设置一个定时器,如果超时都没有新的请求到来,则触发超时事件。这里涉及定时器的设置和重置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // 是不是最后一个响应
if (res._last) {
// 是则销毁socket
if (typeof socket.destroySoon === 'function') {
socket.destroySoon();
} else {
socket.end();
}
} else if (state.outgoing.length === 0) {
// 没有待处理的响应了,则重新设置超时时间,等待请求的到来,一定时间内没有请求则触发timeout事件
if (server.keepAliveTimeout && typeof socket.setTimeout === 'function') {
socket.setTimeout(server.keepAliveTimeout);
state.keepAliveTimeoutSet = true;
}
}
|
每次响应结束的时候,Node.js首先会判断当前响应是不是最后一个,例如读端不可读了,说明不会又请求到来了,也不会有响应了,那么就不需要保持这个TCP连接。如果当前响应不是最后一个,则Node.js会根据keepAliveTimeout的值做下一步判断,如果keepAliveTimeout 非空,则设置定时器,如果keepAliveTimeout 时间内都没有新的请求则触发timeout事件。那么如果有新请求到来,则需要重置这个定时器。Node.js在收到新请求的第一个请求包中,重置该定时器。
| function onParserExecuteCommon(server, socket, parser, state, ret, d) {
resetSocketTimeout(server, socket, state);
}
function resetSocketTimeout(server, socket, state) {
if (!state.keepAliveTimeoutSet)
return;
socket.setTimeout(server.timeout || 0);
state.keepAliveTimeoutSet = false;
}
|
onParserExecuteCommon会在每次收到数据时执行,然后Node.js会重置定时器为server.timeout的值。
18.4 Agent
本节我们先分析Agent模块的实现,Agent对TCP连接进行了池化管理。简单的情况下,客户端发送一个HTTP请求之前,首先建立一个TCP连接,收到响应后会立刻关闭TCP连接。但是我们知道TCP的三次握手是比较耗时的。所以如果我们能复用TCP连接,在一个TCP连接上发送多个HTTP请求和接收多个HTTP响应,那么在性能上面就会得到很大的提升。Agent的作用就是复用TCP连接。不过Agent的模式是在一个TCP连接上串行地发送请求和接收响应,不支持HTTP PipeLine模式。下面我们看一下Agent模块的具体实现。看它是如何实现TCP连接复用的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | function Agent(options) {
if (!(this instanceof Agent))
return new Agent(options);
EventEmitter.call(this);
this.defaultPort = 80;
this.protocol = 'http:';
this.options = { ...options };
// path字段表示是本机的进程间通信时使用的路径,比如Unix域路径
this.options.path = null;
// socket个数达到阈值后,等待空闲socket的请求
this.requests = {};
// 正在使用的socket
this.sockets = {};
// 空闲socket
this.freeSockets = {};
// 空闲socket的存活时间
this.keepAliveMsecs = this.options.keepAliveMsecs || 1000;
/*
用完的socket是否放到空闲队列,
开启keepalive才会放到空闲队列,
不开启keepalive
还有等待socket的请求则复用socket
没有等待socket的请求则直接销毁socket
*/
this.keepAlive = this.options.keepAlive || false;
// 最大的socket个数,包括正在使用的和空闲的socket
this.maxSockets = this.options.maxSockets
|| Agent.defaultMaxSockets;
// 最大的空闲socket个数
this.maxFreeSockets = this.options.maxFreeSockets || 256;
}
|
Agent维护了几个数据结构,分别是等待socket的请求、正在使用的socket、空闲socket。每一个数据结构是一个对象,对象的key是根据HTTP请求参数计算的。对象的值是一个队列。具体结构如图18-7所示。
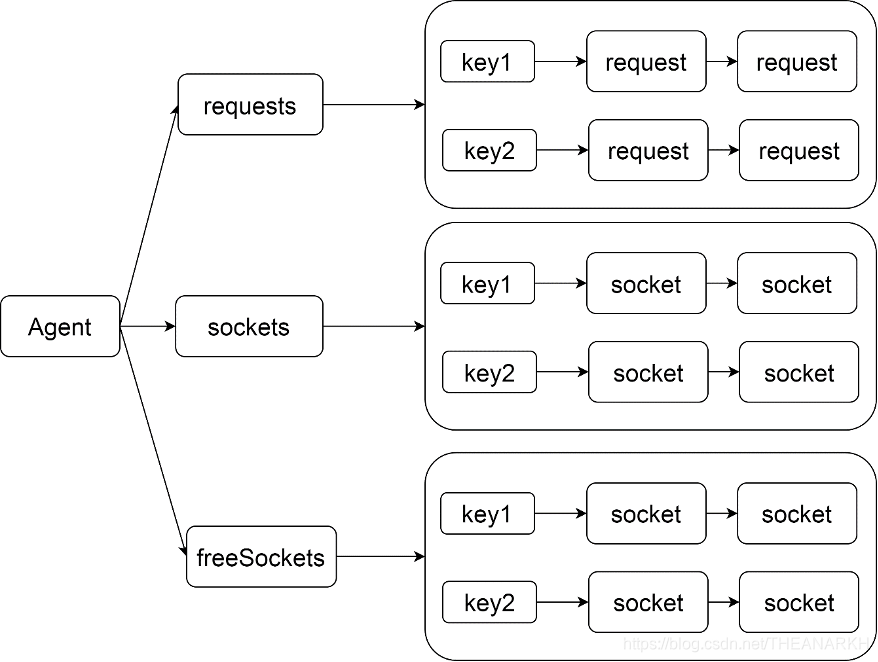
图18-7
下面我们看一下Agent模块的具体实现。
18.4.1 key的计算
key的计算是池化管理的核心。正确地设计key的计算规则,才能更好地利用池化带来的好处。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // 一个请求对应的key
Agent.prototype.getName = function getName(options) {
let name = options.host || 'localhost';
name += ':';
if (options.port)
name += options.port;
name += ':';
if (options.localAddress)
name += options.localAddress;
if (options.family === 4 || options.family === 6)
name += `:${options.family}`;
if (options.socketPath)
name += `:${options.socketPath}`;
return name;
};
|
我们看到key由host、port、本地地址、地址簇类型、unix路径计算而来。所以不同的请求只有这些因子都一样的情况下才能复用连接。另外我们看到Agent支持Unix域。
18.4.2 创建一个socket
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 | function createSocket(req, options, cb) {
options = { ...options, ...this.options };
// 计算key
const name = this.getName(options);
options._agentKey = name;
options.encoding = null;
let called = false;
// 创建socket完毕后执行的回调
const oncreate = (err, s) => {
if (called)
return;
called = true;
if (err)
return cb(err);
if (!this.sockets[name]) {
this.sockets[name] = [];
}
// 插入正在使用的socket队列
this.sockets[name].push(s);
// 监听socket的一些事件,用于回收socket
installListeners(this, s, options);
// 有可用socket,通知调用方
cb(null, s);
};
// 创建一个新的socket,使用net.createConnection
const newSocket = this.createConnection(options, oncreate);
if (newSocket)
oncreate(null, newSocket);
}
function installListeners(agent, s, options) {
/*
socket触发空闲事件的处理函数,告诉agent该socket空闲了,
agent会回收该socket到空闲队列
*/
function onFree() {
agent.emit('free', s, options);
}
/*
监听socket空闲事件,调用方使用完socket后触发,
通知agent socket用完了
*/
s.on('free', onFree);
function onClose(err) {
agent.removeSocket(s, options);
}
// socket关闭则agent会从socket队列中删除它
s.on('close', onClose);
function onRemove() {
agent.removeSocket(s, options);
s.removeListener('close', onClose);
s.removeListener('free', onFree);
s.removeListener('agentRemove', onRemove);
}
// agent被移除
s.on('agentRemove', onRemove);
}
|
创建socket的主要逻辑如下
1 调用net模块创建一个socket(TCP或者Unix域),然后插入使用中的socket队列,最后通知调用方socket创建成功。
2 监听socket的close、free事件和agentRemove事件,触发时从队列中删除socket。
18.4.3 删除socket
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38 | // 把socket从正在使用队列或者空闲队列中移出
function removeSocket(s, options) {
const name = this.getName(options);
const sets = [this.sockets];
/*
socket不可写了,则有可能是存在空闲的队列中,
所以需要遍历空闲队列,因为removeSocket只会在
使用完socket或者socket关闭的时候被调用,前者只有在
可写状态时会调用,后者是不可写的
*/
if (!s.writable)
sets.push(this.freeSockets);
// 从队列中删除对应的socket
for (const sockets of sets) {
if (sockets[name]) {
const index = sockets[name].indexOf(s);
if (index !== -1) {
sockets[name].splice(index, 1);
// Don't leak
if (sockets[name].length === 0)
delete sockets[name];
}
}
}
/*
如果还有在等待socekt的请求,则创建socket去处理它,
因为socket数已经减一了,说明socket个数还没有达到阈值
但是这里应该先判断是否还有空闲的socket,有则可以复用,
没有则创建新的socket
*/
if (this.requests[name] && this.requests[name].length) {
const req = this.requests[name][0];
const socketCreationHandler = handleSocketCreation(this,
req,
false);
this.createSocket(req, options, socketCreationHandler);
}
};
|
前面已经分析过,Agent维护了两个socket队列,删除socket就是从这两个队列中找到对应的socket,然后移除它。移除后需要判断一下是否还有等待socket的请求队列,有的话就新建一个socket去处理它。因为移除了一个socket,就说明可以新增一个socket。
18.4.4 设置socket keepalive
当socket被使用完并且被插入空闲队列后,需要重新设置socket的keepalive值。等到超时会自动关闭socket。在一个socket上调用一次setKeepAlive就可以了,这里可能会导致多次调用setKeepAlive,不过也没有影响。
| function keepSocketAlive(socket) {
socket.setKeepAlive(true, this.keepAliveMsecs);
socket.unref();
return true;
};
|
另外需要设置ref标记,防止该socket阻止事件循环的退出,因为该socket是空闲的,不应该影响事件循环的退出。
18.4.5 复用socket
| function reuseSocket(socket, req) {
req.reusedSocket = true;
socket.ref();
};
|
重新使用该socket,需要修改ref标记,阻止事件循环退出,并标记请求使用的是复用socket。
18.4.6 销毁Agent
| function destroy() {
for (const set of [this.freeSockets, this.sockets]) {
for (const key of ObjectKeys(set)) {
for (const setName of set[key]) {
setName.destroy();
}
}
}
};
|
因为Agent本质上是一个socket池,销毁Agent即销毁池里维护的所有socket。
18.4.7 使用连接池
我们看一下如何使用Agent。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56 | function addRequest(req, options, port, localAddress) {
// 参数处理
if (typeof options === 'string') {
options = {
host: options,
port,
localAddress
};
}
options = { ...options, ...this.options };
if (options.socketPath)
options.path = options.socketPath;
if (!options.servername && options.servername !== '')
options.servername = calculateServerName(options, req);
// 拿到请求对应的key
const name = this.getName(options);
// 该key还没有在使用的socekt则初始化数据结构
if (!this.sockets[name]) {
this.sockets[name] = [];
}
// 该key对应的空闲socket列表
const freeLen = this.freeSockets[name] ?
this.freeSockets[name].length : 0;
// 该key对应的所有socket个数
const sockLen = freeLen + this.sockets[name].length;
// 该key有对应的空闲socekt
if (freeLen) {
// 获取一个该key对应的空闲socket
const socket = this.freeSockets[name].shift();
// 取完了删除,防止内存泄漏
if (!this.freeSockets[name].length)
delete this.freeSockets[name];
// 设置ref标记,因为正在使用该socket
this.reuseSocket(socket, req);
// 设置请求对应的socket
setRequestSocket(this, req, socket);
// 插入正在使用的socket队列
this.sockets[name].push(socket);
} else if (sockLen < this.maxSockets) {
/*
如果该key没有对应的空闲socket并且使用的
socket个数还没有得到阈值,则继续创建
*/
this.createSocket(req,
options,
handleSocketCreation(this, req, true));
} else {
// 等待该key下有空闲的socket
if (!this.requests[name]) {
this.requests[name] = [];
}
this.requests[name].push(req);
}
}
|
当我们需要发送一个HTTP请求的时候,我们可以通过Agent的addRequest方法把请求托管到Agent中,当有可用的socket时,Agent会通知我们。addRequest的代码很长,主要分为三种情况。 1 有空闲socket,则直接复用,并插入正在使用的socket队列中
我们主要看一下setRequestSocket函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | function setRequestSocket(agent, req, socket) {
// 通知请求socket创建成功
req.onSocket(socket);
const agentTimeout = agent.options.timeout || 0;
if (req.timeout === undefined || req.timeout === agentTimeout)
{
return;
}
// 开启一个定时器,过期后触发timeout事件
socket.setTimeout(req.timeout);
/*
监听响应事件,响应结束后需要重新设置超时时间,
开启下一个请求的超时计算,否则会提前过期
*/
req.once('response', (res) => {
res.once('end', () => {
if (socket.timeout !== agentTimeout) {
socket.setTimeout(agentTimeout);
}
});
});
}
|
setRequestSocket函数通过req.onSocket(socket)通知调用方有可用socket。然后如果请求设置了超时时间则设置socket的超时时间,即请求的超时时间。最后监听响应结束事件,重新设置超时时间。 2 没有空闲socket,但是使用的socket个数还没有达到阈值,则创建新的socket。
我们主要分析创建socket后的回调handleSocketCreation。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | function handleSocketCreation(agent, request, informRequest) {
return function handleSocketCreation_Inner(err, socket) {
if (err) {
process.nextTick(emitErrorNT, request, err);
return;
}
/*
是否需要直接通知请求方,这时候request不是来自等待
socket的requests队列, 而是来自调用方,见addRequest
*/
if (informRequest)
setRequestSocket(agent, request, socket);
else
/*
不直接通知,先告诉agent有空闲的socket,
agent会判断是否有正在等待socket的请求,有则处理
*/
socket.emit('free');
};
}
|
3 不满足1,2,则把请求插入等待socket队列。
插入等待socket队列后,当有socket空闲时会触发free事件,我们看一下该事件的处理逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58 | // 监听socket空闲事件
this.on('free', (socket, options) => {
const name = this.getName(options);
// socket还可写并且还有等待socket的请求,则复用socket
if (socket.writable &&
this.requests[name] && this.requests[name].length) {
// 拿到一个等待socket的请求,然后通知它有socket可用
const req = this.requests[name].shift();
setRequestSocket(this, req, socket);
// 没有等待socket的请求则删除,防止内存泄漏
if (this.requests[name].length === 0) {
// don't leak
delete this.requests[name];
}
} else {
// socket不可用写或者没有等待socket的请求了
const req = socket._httpMessage;
// socket可写并且请求设置了允许使用复用的socket
if (req &&
req.shouldKeepAlive &&
socket.writable &&
this.keepAlive) {
let freeSockets = this.freeSockets[name];
// 该key下当前的空闲socket个数
const freeLen = freeSockets ? freeSockets.length : 0;
let count = freeLen;
// 正在使用的socket个数
if (this.sockets[name])
count += this.sockets[name].length;
/*
该key使用的socket个数达到阈值或者空闲socket达到阈值,
则不复用socket,直接销毁socket
*/
if (count > this.maxSockets ||
freeLen >= this.maxFreeSockets) {
socket.destroy();
} else if (this.keepSocketAlive(socket)) {
/*
重新设置socket的存活时间,设置失败说明无法重新设置存活时
间,则说明可能不支持复用
*/
freeSockets = freeSockets || [];
this.freeSockets[name] = freeSockets;
socket[async_id_symbol] = -1;
socket._httpMessage = null;
// 把socket从正在使用队列中移除
this.removeSocket(socket, options);
// 插入socket空闲队列
freeSockets.push(socket);
} else {
// 不复用则直接销毁
socket.destroy();
}
} else {
socket.destroy();
}
}
});
|
当有socket空闲时,分为以下几种情况
1 如果有等待socket的请求,则直接复用socket。
2 如果没有等待socket的请求,允许复用并且socket个数没有达到阈值则插入空闲队列。
3 直接销毁
18.4.8 测试例子
客户端
| const http = require('http');
const keepAliveAgent = new http.Agent({ keepAlive: true, maxSockets: 1 });
const options = {port: 10000, method: 'GET', host: '127.0.0.1',}
options.agent = keepAliveAgent;
http.get(options, () => {});
http.get(options, () => {});
console.log(options.agent.requests)
|
服务器
| let i =0;
const net = require('net');
net.createServer((socket) => {
console.log(++i);
}).listen(10000);
|
在例子中,首先创建了一个tcp服务器。然后在客户端使用agent。但是maxSocket的值为1,代表最多只能有一个socket,而这时候客户端发送两个请求,所以有一个请求就会在排队。服务器也只收到了一个连接。